안녕하세요, 이번 포스팅 할 내용은, gTTs, SpeechRecognition 라이브러리를 이용해서 음성을 텍스트로 변환하는 코드에 대해서 다룰려고 합니다. 더불어 제가 말한 거에 대답하는 AI 로봇 코드도 설명 드리도록 하겠습니다.


그럼 제가 나름대로 이해한 gTTs, SpeechRecognition 라이브러리에 대해서 차근 차근 설명해 드리도록 하겠습니다.
음성 -> 텍스트 변환 파이썬(python) 라이브러리
:음성을 텍스트 변환하는 파이썬(python) 라이브러리는 아래와 같습니다.
=========================================================
import speech_recognition as sr
- 내부 함수로는 아래와 같습니다.
1) Recognizer()
2) Microphone()
3) listen()
4) recognize_google()
=========================================================
- 아래 라이브러리를 사용하기 위해서는 일단, 라이브러리를 설치를 해야 합니다. 근데 보통 라이브러리 이름과 설치하는 명령어가 똑같은데, "speech_recognition" 라이브러리 설치 명령어는 아래와 같습니다.
: pip install speechrecognition (자세히 보면 "_" 가 없습니다. 주의해서 입력하시면 됩니다.)
- 설치를 하면 아래와 같은 구문이 나오고, 성공적으로 설치 된 상태를 표현해 줍니다.

내말에 대답하는 AI 로봇 만들기 위한 라이브러리
: 위에서 내 말을 텍스트로 전환 해주는 코드에 더불어, 내 말에 대답해 주는 AI 로봇을 만들어 보려고 합니다. AI 로봇 구현을 위해서는 아래 라이브러리가 필요합니다.
============================================================================
# gTTs (Google Text to speech)의 약자로, TEXT를 speech 형식으로 출력해주는 라이브러리 입니다.
from gtts import gTTS
# 기본 라이브러리로서, 추가적인 작업을 가미할 때 필요한 라이브러리 입니다.
# 생성된 음성파일을 중복으로 인한 Error를 피하기 위해서, 사용하는 파일 삭제하는 라이브러리를 사용할 예정.
import os
import time
# gTTs (Google Text to speech)의 약자로, TEXT를 speech 형식으로 출력해주는 라이브러리 입니다.
import playsound============================================================================
- os, time의 라이브러리는 기본적으로 제공하는 라이브러리 이므로, gTTs만 추가적으로 설치하시면 됩니다. 설치 구문은 아래와 같습니다. 위와 같이 설치 완료 화면이 나오면 설치가 완료가 된 것입니다.
: pip install gTTs
전체 코드 구현
: 위에 1, 2번 항목의 라이브러리를 다 설치 완료하였으니, 본격적으로 코드를 구현해보도록 하겠습니다. 코드 구현은 아래와 같습니다.
================================================================================
# 음성 인식하는 라이브러리
import speech_recognition as sr
# gTTs (Google Text to speech)의 약자로, TEXT를 speech 형식으로 출력해주는 라이브러리 입니다.
from gtts import gTTS
# 기본 라이브러리로서, 추가적인 작업을 가미할 때 필요한 라이브러리 입니다.
import os
import time
# gTTs (Google Text to speech)의 약자로, TEXT를 speech 형식으로 출력해주는 라이브러리 입니다.
import playsound
def reply(text, a):
tts= gTTS(text=text, lang='en')
filename = 'D:\\' + text + str(a) +'.mp3' # 음성 파일을 저장하는 경로와 파이명 지정
# if os.path.isfile(filename):
# os.remove(file)
tts.save(filename)
playsound.playsound(filename)
def Voice_Recognition(): # 음성 인식하는 함수 선언
r = sr.Recognizer()
with sr.Microphone() as source:
audio = r.listen(source)
said = " "
try:
said = r.recognize_google(audio)
print(said)
except Exception as e:
print("Exception: " + str(e))
return said
i = 0
list01 = []
while True: # 원하는 만큼 물어보고 위한 무한 루트 선언
text = Voice_Recognition()
if "hi" in text: # 1번째 음성 인식에 따른, AI 로봇의 답변 입력
answer01 = 'hilongtimenoseehowareyou'
reply(answer01, i)
i = i + 1
# 2번째 음성 인식에 따른, AI 로봇의 답변 입력
elif "how are you, can you tell me your name" in text:
answer01 = 'MynameisDavey'
reply("MynameisDavey",i)
i = i + 1
# 코드를 끝내는 음성 선언
elif "bye" in text:
break
# 음성파일 이름을 리스트화 하는 코드
list01.append(answer01 + str(i-1) + '.mp3')
# 코드가 끝나면 음성파일을 삭제하는 코드
for item in list01:
# modi = '.'
print(item)
os.remove('D:/' +item)
================================================================================
- 위의 코드를 실행을 출력창에는 아래와 같이 출력되는 걸 확인 하실 수 있습니다. 아래 결과 창을 보시면, 2번째 질문은 제가 3번 했고, 그거에 대해서 답변을 한게, 저장이 된 파일이, MynameisDavey0~3.mp3 파일이고, 이게 리스트 화 되었습니다. 그리고 나서, 이걸 For 문을 돌려서 삭제를 한 것이지요. 왜냐하면, 똑같은 질문을 하면 오류가 나기 때문입니다. 한 번 아래 코드를 생략하고 돌려보시면, 인지하실 것입니다.
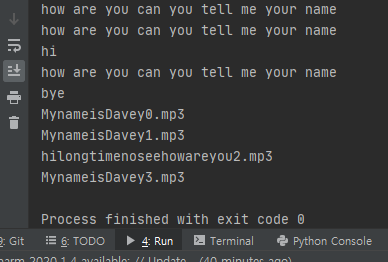
이상입니다. 지금까지 gTTs, SpeechRecognition 라이브러리를 이용해서 음성을 텍스트로 변환하는 코드에 대해서 포스팅 작성하였습니다. 물론 다른 라이브러리를 사용해서 구현을 했지만, 중간 중간에, 제가 구현하고 싶은 사항에 대해서 trouble shooting 하느라고 시간을 좀 많이 허비한 거 같습니다. 정말, 이런 거 보면, 프로그래밍 하시는 분들, 존경 스럽습니다.
너무 멋있지 않나요?! 물론 모든 일을 하시는 분들 다 멋있지만, 요즘 너무 프로그래밍에 꼿혀 있는 거 같아서 그런가, 너무 Fancy 한 거 같습니다. 무튼, 한 번 보시고, 공부 해보시길 추천 드립니다. 그럼 같이 공부하고 같이 성장해 나가시죠! 감사합니다.
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁 드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치 하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]




댓글