안녕하세요, 이번 포스팅에서는 Python의 Pandas 패키지 함수 중에 DataFrame이라는 함수를 어떻게 활용하는지에 대한 내용으로 작성해보도록 하겠습니다. 쉬운 이해를 돕기 위해서 예시를 통해 설명드리도록 하겠습니다.

Pandas DataFrame 이용하기
: Pandas 패키지를 잘 이용을 하려면 numpy 패키지도 같이 혼용해서 사용하시면 더 편리하게 사용하실 수 있습니다. 그러므로 Pandas 와 numpy의 패키지를 같이 선언을 합니다.
#pandas와 numpy의 패키지를 선언함.
import pandas as pd
import numpy as np
추가적으로 말씀 드리지만, "as pd", "as np"는 pandas와 numpy의 풀네임을 쓰지 않고 단축 단어로 사용하기 위한 것입니다. 즉 다른 단어로 쓰셔도 무방합니다. 제가 "pd", "np"를 쓴 이유는 정말 대부분의 사람들이 이렇게 쓰고 있고 이것에 대한 거부감이 없어서입니다.
그럼 본격적으로 DataFrame을 이용해보도록 하겠습니다. 이용하기 전에 간단하게 DataFrame을 설명을 드리면 (제 개인적인 지식을 토대로 설명드리니, 공식적인 설명이랑 문구는 다를 수 있는 점 참조 부탁드립니다.) 말 그대로 Frame 화하는 것입니다. 좀 쉽게 얘기하면 여러 가지의 데이터를 좀 개량하기 위해 테이블화 하는 함수라고 생각합니다. 그럼 예제를 통해서 설명을 드리도록 하겠습니다. 아래와 같이 각 도시 이름을 가진 Dictionary를 먼저 선언을 합니다. 그 Dictionary를 바로 DataFrame에 집어넣으면 바로 Frame 화 됩니다.
# Data Frame 내용을 Dictionary 로 정리해서 준비함.
Test_Data = {'City': ['Seoul', 'Busan', 'Paris', 'London', 'NewYork'],
'Year To Visit': [2021, 2020, 2015, 2016, 2015],
'Impression (Out of 10)': [6, 7, 6, 4, 9]}
# Dictionary로 준비한 내용을 간단하게 DataFrame 화 할 수 있음.
df1 = pd.DataFrame(Test_Data)
print(df1)
print()
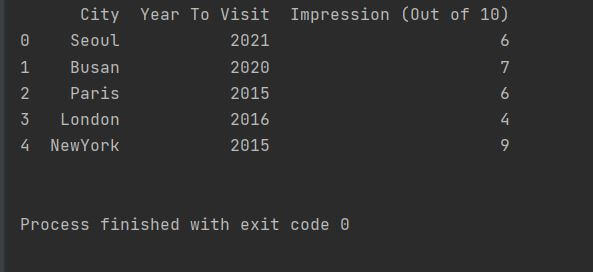
위 코드를 실행을 해보면 아래와 같은 결과를 보실 수 있습니다. 일단 Dictionary의 Key 값이 Column으로 지정이 되는 걸 확인 하실 수 있습니다. 그리고 인덱스는 '0'부터 시작해서 Data 개수만큼 부여가 됩니다.
그럼 데이터를 개량하기 위한 기초 코드인 DataFrame의 내부 속성값을 출력하는 것을 해보도록 하겠습니다. 아래 코드를 이용하면 내부 속성 값이 출력이 되는 걸 확인하실 수 있습니다. 그리고 잘 보시면, 각 행이 np.array를 통해서 출력되는 값과 비슷하다는 걸 발견하실 수 있습니다. 쉬운 이해를 돕기 위해서 아래와 같이 예제로, City 쪽 List를 np.array 화 시켜보도록 하겠습니다.
# DataFrame 화 Data의 내부 속성 값을 출력함
# 출력을 해보시면 numpy를 통해서 nparray 형식으로 변환한 내용과 같은 내용 출력되는 걸 확인 하실 수 있습니다.
test_df_value = df1.values
print(test_df_value)
print()
# 쉬운 이해를 돕기 위해서 아래와 같이 예제로, City 쪽 List를 np.array 화 시켜보도록 하겠습니다.
test_numpy = np.array(['Seoul', 'Busan', 'Paris', 'London', 'NewYork'])
print(test_numpy)
print()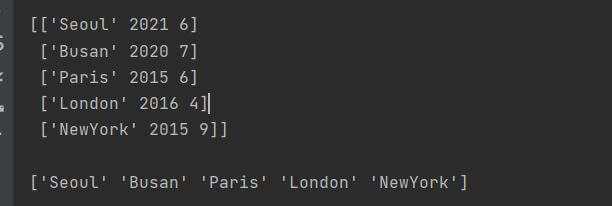
그리고 위의 내용을 보시면 DataFrame 화 시키면 행과 열의 구조를 가진 데이터가 생기게 되는 걸 확인 하실 수 있습니다. 해당 데이터를 다 출력하지 않고 행의 개수만 알고 싶을 때는 Index 내용을 출력을 하면 아실 수 있습니다. 행 방향의 Index의 내용은 아래 코드를 통해서 출력이 가능합니다. 추가적으로 열 방향의 Column 내용도 출력이 가능한 코드도 같이 추가하도록 하겠습니다.
# 행 방향의 index의 내용을 출력 가능
test_df_index = df1.index
print(test_df_index)
print()
# 열 방향의 Column 내용을 출력 가능
test_df_columns = df1.columns
print(test_df_columns)
print()

DataFrame Index와 Column 이름 설정 하기
: DataFrame 된 내용을 기반으로 Index와 Column 이름을 설정할 수 있습니다. 즉 인덱트가 0부터 행 개수만큼 정해져 있지만 이 Index에 대해서 Column 같이 이름을 지정할 수 있습니다. 그리고 Column 들의 Category 이름도 같이 지정할 수가 있습니다. 아래 내용대로 지정을 해보도록 하겠습니다. 그리고 코드도 같이 첨부하도록 하겠습니다.
1) Column의 Category 이름 : 'Name of City'
2) Index 의 Column 이름 : 'No. of Row'
# 인덱스와 Column에 대해서 이름을 설정 가능
df1.index.name = 'No. of Row'
test_df_index_name = df1.index.name
print(test_df_index_name)
print()
df1.columns.name = 'Name of City'
test_df_columns_name = df1.columns.name
print(test_df_columns_name)
print()
print(df1)
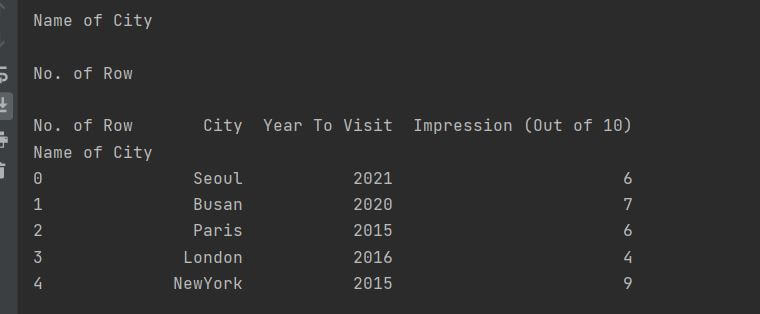
위 코드를 실행을 해보면 아래와 같이 Column의 Category 이름과 Indexd의 Column 이름이 배정이 된 것을 확인을 하실 수 있습니다. 이렇게 코드를 통해서 맞춤 테이블 형식을 만들 수가 있습니다.
이상입니다. 지금까지 Panda 패키지를 이용하여 DataFrame을 어떻게 이용하는지에 대한 내용과 내부 Column Category와 Index Column을 어떻게 설정하는지에 대한 내용으로 포스팅을 작성하였습니다. 위 코드를 이용하여 자신만의 Data Table을 만들어 보시길 추천드립니다. 이만 마무리하도록 하겠습니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을 때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]
'파이썬 (Python) > Pandas' 카테고리의 다른 글
| Python Panda Column 삭제 및 원하는 행 Data 출력 (0) | 2021.04.17 |
|---|---|
| Python Panda Seriese 로 Data 테이블화 하기 + Column 추가 및 Data 사칙 계산 (0) | 2021.04.17 |
| Python Panda DataFrame 에서 선별적으로 Data 출력하기 (0) | 2021.04.05 |
| Python Pandas DataFrame Column과 Index 설정하는 방법 (0) | 2021.03.21 |
| Python 파이썬 데이터 조작과 분석을 위한 절대 병기 Pandas 라이브러리 파헤치기 Part 1 (1) | 2021.01.28 |




댓글