안녕하세요, Davey 입니다. 오늘 제가 포스팅할 내용은, 지난 번에 포스팅한 선형회귀 모델링 작업을 Tensorflow로 하는 법에 대한 내용입니다. Tensorflow를 이용하여 모델링을 해보도록 하겠습니다.

지난 번에 사용한 라이브러리는 scikit-learn이라는 패키지 입니다. 하지만 이번에 사용할 내용은 이전에 포스팅한 Tensorflow 를 이용한 모델링 작업입니다. 일단 Tensorflow에 대해서 간략하게 정리한 포스팅 먼저 보고 오시면 이해가 더 빠르실 겁니다.
Python 파이썬 + 구글이 만든 괴물같은 파워풀한 라이브러리 텐서플로우(tensorflow) + 사칙연산 및 행
안녕하세요, Davey 입니다. 오늘이 포스팅할 내용은, 구글이 만든 괴물같은 라이브러리, 텐서플로우(tensorflow)에 대한 내용이며, 제가 이해한 부분을 코딩하실 때 조금이나마 도움이 되시라고 설
davey.tistory.com
- 그럼 위 포스팅을 참조하셨다라고 간주하고, Tensorflow에 대해서는 별도의 설명없이, 바로 어떻게 모델링 작업을 하는지에 대해서 설명 드리도록 하겠습니다.
- 이전에도 몇번 말씀 드린 대로, python을 구현하고 coding하기 위해서는, 필요한 라이브러리의 import가 필요합니다. 그럼 아래와 같이 import 해보도록 하겠습니다.
Tensorflow를 이용한 모델링 작업을 위한 라이브러리 Import
: 아래와 같이 Import 구문 참조 하시면 됩니다. 필요한 라이브러리는 아래에서 보시는 것과 같이 4개입니다. 각 라이브러리에 대한 설명을 아래 내용 참조 하세요.
==================================================================================
# 모델링 작업을 위한 라이브러리 tensorflow 그리고, "as tf" 는 코드 작업 편의성을 위한 줄임말 선언
import tensorflow as tf
# 배열을 위한 라이브러리
import numpy as np
# 결과값과 입력값의 시각화를 위한 라이브러리
import matplotlib.pyplot as plt
# 랜덤한 값을 구현하기 위한 라이브러리
import random
==================================================================================
Initial Data를 구현하는 코드
:
기존에 정립화, Verified 된 Data가 있으면 정말 편한데, 이렇게 그냥 예시로 하거나, 테스트하는 Code 구현 때는, 기존 데이터를 어떤 걸 쓸지에 대한 고민을 하게 됩니다. 그래서 저는 여러가지 Initial Data 구현 방법을 알려 드릴테니, 원하신 방법대로 구현하시면 됩니다.
1) 정립화 되어 있는 Data
- 정립화 되어 있는 Data가 있는 경우에는 아래와 같이 하나 하나 원하는 값을 입력하시면 됩니다. 물론 pandas를 이용하여,
excel data를 불러와서 구현하셔도 됩니다. 이 부분은, 아래 posting 참조 해주세요.
머신 러닝(Machine Learning) - 선형 회귀 모델링 Analystical Solution 사용 방법
안녕하세요, 오늘 포스팅 할 내용은 머신러닝의 한 부분인, 선형 모델링 Analystical Solution 대한 내용입니다. 요즘 핫한 내용인 머신 러닝(Machine Learning) 구현을 위해 구현해야 되는 모델을 도출하
davey.tistory.com
2) numpy random 모듈을 이용하여, random한 Initial Data를 선언
- 제목 그대로, numpy random 모듈을 이용하여, random한 Initial Data를 선언하여, 초기 값을 세팅하는 방법입니다.
아래 Code 참조 하시면 됩니다.
============================================================================
# Initial Data를 담을 수 있는 LIST 변수 2개 선언
resource01 = []
resource02 = []
# numpy random 모듈을 이용하여, random한 Initial Data를 선언
a1 = np.random.random(10)
b1 = np.random.random(10)
for i in range(10):
resource01.append(a1[i])
resource02.append(b1[i])
# 리스트 화 된 Data를 배열화를 합니다.
resource01_mod = np.array(resource01)
resource02_mod = np.array(resource02)
============================================================================
3) 임의의 식을 통해서 Initial Data를 선언
- 제목 그대로, 임의의 식을 선언하여, 그 출력 값을 Initial Data로 선언을 하는 것입니다. 약간의 규칙적인 Data 값이 나와서, 결과값도 좀 일괄적으로 나와서, 보기에는 좋습니다. 자세한 사항은, 아래 Code 참조 하시면 됩니다.
============================================================================
# Initial Data를 담을 수 있는 LIST 변수 2개 선언
resource01 = []
resource02 = []
# 임의의 식을 통해서 Initial Data를 선언
for i in range(10):
resource01.append(1 + i + (i + 1)/10 + (i + 1)/5)
resource02.append(2 + i**2 + (i + 2)/10 + (i + 2)/5)
# 리스트 화 된 Data를 배열화를 합니다.
resource01_mod = np.array(resource01)
resource02_mod = np.array(resource02)
============================================================================
Tensorflow를 이용한 모델링 작업 Main 코드
: 1,2번 항목에서 언급한 내용, 즉 라이브러리 선언 및 Initial Data 작업을 하고 나면, 이제 Main Code를 작성을 해야 합니다. Code는 아래와 같습니다. 위 1, 2번 항목도 같이 합쳐서 구현하도록 하겠습니다. Initial Data 정립은, numpy random모듈을 이용하여, random한 Initial Data를 선언 하는 방법으로 구현하도록 하겠습니다.
============================================================================
# 모델링 작업을 위한 라이브러리 tensorflow 그리고, "as tf" 는 코드 작업 편의성을 위한 줄임말 선언
import tensorflow as tf
# 배열을 위한 라이브러리
import numpy as np
# 결과값과 입력값의 시각화를 위한 라이브러리
import matplotlib.pyplot as plt
# 랜덤한 값을 구현하기 위한 라이브러리
import random
# Initial Data를 담을 수 있는 LIST 변수 2개 선언
resource01 = []
resource02 = []
# numpy random 모듈을 이용하여, random한 Initial Data를 선언
a1 = np.random.random(10)
b1 = np.random.random(10)
for i in range(10):
resource01.append(a1[i])
resource02.append(b1[i])
# 리스트 화 된 Data를 배열화를 합니다.
resource01_mod = np.array(resource01)
resource02_mod = np.array(resource02)
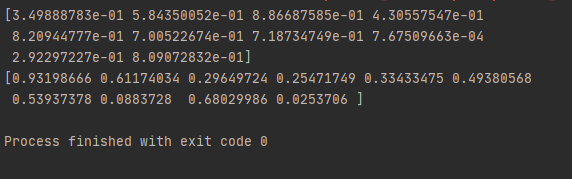
- 위의 resource01_mod, resource02_mod 를 출력을 해보면 아래와 같이 결과 값을 보실 수 있습니다. 하지만, 출력 할 때마다, 즉 코드를 실행할 때마다, 다른 값이 출력이 됩니다.
-> 첫번째 구현 시 출력 값
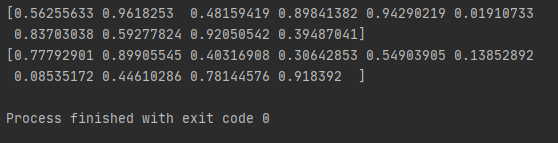
-> 두번째 구현 시 출력 값
# numpy로 배열화 한 속성값의 배열 형태를 n x 1 형태로 변경을 해줍니다.
test_data1 = resource01_mod.reshape(-1,1) # 몇개의 행인지를 계산하기 싫을 때는, "-1"을 이용해도 무방하다.
test_data2 = resource02_mod.reshape(-1,1) # 몇개의 행인지를 계산하기 싫을 때는, "-1"을 이용해도 무방하다.
# 초기 Parameter 값을 random 값으로 입력함. 방법은 여러가지기 있음
# 1) numpy 를 이용한 random 초기값 세팅
a = np.random.rand(1)
b = np.random.rand(1)
Parameter_a = a[0]
Parameter_b = b[0]
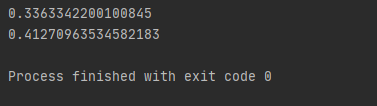
print(Parameter_a)
print(Parameter_b)
- 위의 초기 값을 출력하면 아래와 같이 random한 값이 출력이 됩니다.
# 2) tensorflow 를 이용한 random 초기값 세팅
Parameter_a = tf.Variable(random.random())
Parameter_b = tf.Variable(random.random())
print(Parameter_a)
print(Parameter_b)
- 위의 초기 값을 출력하면 아래와 같이 random한 값이 출력이 됩니다. 즉, 둘 중 하나만 사용하시면 됩니다.

#Error cost Verification 할 수 있는 함수를 선언
def cost_error():
y_new = Parameter_a * test_data1 + Parameter_b
# tensorflow의 reduce_mean 모듈을 시용하여 모델링을 함.
verified_error_cost = tf.reduce_mean((test_data2 - y_new) ** 2)
return verified_error_cost
#Optimizing 알고리즘 모듈 중에 Adam 을 사용함. (Gradient Descent Concept)
optimizing_module = tf.keras.optimizers.Adam(lr=0.07)
# Cost 값이 어떻게 입력이 되었는지를 알아보기 위해서, List를 하나 만듬.
cost_new = []
for i in range(1000):
# 최소의 cost를 찾는, Formula를 아래와 같이, tr.keras 내부 함수인, minimize 써서 쉽게 해결 할 수 있음.
optimizing_module.minimize(cost_error, var_list=[Parameter_a, Parameter_b])
# 위에 만들어 놓은 cost_new 라는 list에 출력되는 각 cost 값을 추가하는 Code
# 여기에서 추가 할 설명은, 각 변수 or 함수에 numpy()를 붙여서, 1차 배열로 변화 해줘야, 출력이 된다는 것도 인지하고 있어야함.
cost_new.append(cost_error().numpy())
# 0, 100, 200 ~ 각 100번째의 값을 출력하라는 code
if i % 100 == 0:
print(i, 'a:', Parameter_a.numpy(), 'b:', Parameter_b.numpy(), 'Error cost:', cost_error().numpy())
# 한 줄 띄어서, 가시성을 높이는 code, 큰 의미는 없음
print()
print('출력되는 최종 Cost 값은 \n',cost_new[999])
cost_x_axis =np.arange(0,1000)
# 그래프 출력을 위해서, 최소값과 최대값의 범위를 가지고, 0.1씩 x 축의 값을 "Plot_x"에 입력
Plot_x = np.arange(min(test_data1), max(test_data1), 0.01)
# 위에 선언한, x 축의 값을 기반으로, Model 식에 대입하여 출력되는 y 축의 값을, Plot_y에 입력.
Plot_y = Parameter_a * Plot_x + Parameter_b
# 그래프 구현을 위해서, matplotlib method를 이용하여, Code를 구현.
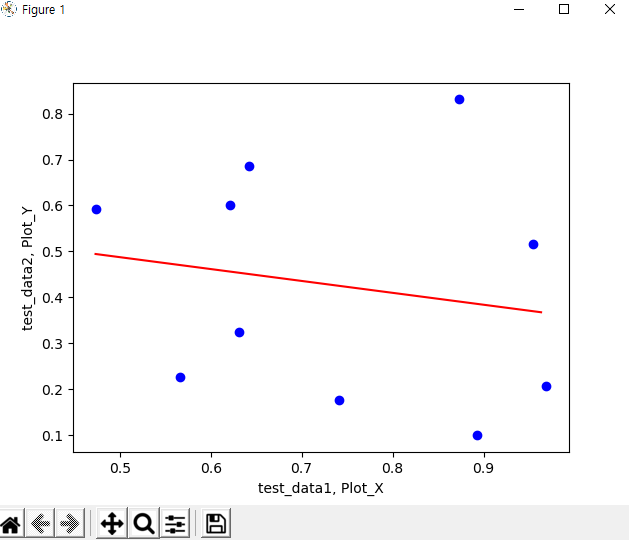
# 모델링한 식을 가지고, Linear한 곡선으로 그래프에 표현
plt.plot(Plot_x,Plot_y, color='red')
# Initial Data 을 Dot로 그래프에 표현
plt.plot(test_data1,test_data2,'bo')
plt.xlabel('test_data1, Plot_X')
plt.ylabel('test_data2, Plot_Y')
plt.show()
# the number of cost verified 값이, 반복한 횟수와 일치하므로, 반복한 횟수를 x axis value로 가져가면서, 그래프를 출력하는 Code를 구현.
plt.plot(cost_x_axis,cost_new, color = 'blue', label='Cost (Error)')
plt.title("Cost (Error) Verification Graph")
plt.xlabel("Repeated Number")
plt.ylabel("Cost (Error) Value")
plt.show()
============================================================================
- 위 Main Code를 실행 시켜 보면 아래와 같은 결과 값을 보실 수 있습니다. 랜덤한 값을 Initial Input Data로 사용하다 보니까, 모델링 결과 값도, 오차가 많이 나는 출력값이 출력이 됩니다. 즉, Initial Data 값에 따라, 출력값도, 달라니는 것을 확인 하실 수 있습니다. Verified 된 Initial 값에 대한 중요성을 다시 한 번 확인 하셨을 거라고 생각합니다.
이상입니다. 지금까지 선형회귀 모델링 작업을 Tensorflow로 하는 법에 대해서 포스팅을 작성하였습니다. 이번 Tensorflow를 이용한 모델링 포함해서, 모델링 작업을 하는데, 정말 다양한 라이브러리가 있는 것을 확인 하셨을 겁니다. 직접적인 식을 이용하여 모델링한 것과, 라이브러리를 이용하여 모델링한 것 등 여러가지 방법을 통해서 모델링 작업을 구현 하 실 수 있습니다.
사실 저는 처음에는 이런 작업을 하는 것에 대해서 너무나도 놀랐고, 이게 구현이 잘만 되면, 최적의 결과를 구현 할 수 있지 않을까? 아니면 최적의 결과는 구현하지 못해도, 결과 값은 어느정도 예측해서, 그 부가적인 요소를 맞출 수 있지 않을까 라는 생각을 하였습니다. 지금은 너무나도 초보지만, 추후 진짜 제가 생각한 것을 구현하는 날에 더 가까이 다가가기 위해서 오늘도 노력하고 내일도 노력하겠습니다. 이 글을 보시는 분들도, 같이 공부해서 같이 성장하시죠! 감사합니다.
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁 드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치 하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]
'파이썬 (Python) > 딥러닝 (Deep Learning)' 카테고리의 다른 글
| Python 파이썬 머신 러닝(Machine Learning) 기초 - 기술 통계량 및 추정량에 대한 이해 (0) | 2021.03.01 |
|---|---|
| Python 파이썬 머신 러닝(Machine Learning) 기초 - 통계학, 머신 러닝 자료 Type (0) | 2021.03.01 |
| 머신 러닝(Machine Learning) - 선형 회귀 모델링 + Scikt-learn 패키지 이용 방법 (0) | 2021.02.28 |
| 머신러닝을 이용한 "You Know Stock" 주식 분석 및 예측 Plot 프로그램 (0) | 2021.02.28 |
| 파이썬 음성을 텍스트로 변환 하고, 내 말에 대답하는 AI 로봇 만들기 + gTTs, SpeechRecognition 라이브러리 (0) | 2021.02.28 |




댓글