안녕하세요, 이번 포스팅은 웹 페이지 크롤링 작업 수행 위한 기초 지식 중에 하나인 requests 라이브러리에 대해서 기재하려고 합니다. 이전 포스팅에 크롤링을 구현하는 법에 대해서 설명을 드린 내용을 이용하여 설명 드리도록 하겠습니다.

저도 사실, 그때 그냥 먼가 먼저 해보면서 배우는 게 더 나을거라고 생각했습니다. 지금도 그게 효율적인 방법 중에 하나라는 거에 대해서는 아직도 어느정도는 동의를 합니다.
하지만, 그런 예도 중요하지만, 기본적인 지식에 대해서 알아야 될 거 같아서 이렇게 크롤링 작업을 위한 기초 지식에 대해
서 포스팅 하려고 합니다. 그럼 제가 나름대로 이해하고 공부한 내용을 기반으로 웹 페이지 크롤링 작업 수행 위한 기초 지식 중에 하나인 requests 라이브러리를 설명 드리도록 하겠습니다.
1. 크롤링 기초 - requests 이해 하기 (GET 모듈)
: 일단 크롤링이라는 의미가 웹 페이지에 있는 정보나 데이터를 반복적인 코드를 통해서 가져오는 일련의 작업이기에, 이 웹페이지를 불러오고, 읽는 라이브러리를 이용하여야 합니다. 그게 바로 requests 입니다. requests 선언 부터 어떻게 구현하는지에 대해서 제가 간단한 예를 들어서 설명 해 드리도록 하겠습니다. 아래 예제는 "GET" 모듈을 사용하는 예입니다.
==================================================================================
# requests 라이브러리를 선언을 함
import requests
# 접속하여, 정보를 가지고 오고 싶어하는 URL을 internet_Url01 에 입력함.
internet_Url01 = "https://www.naver.com/"
# requests.get 모듈을 이용하여, internet_Url01에 입력된 URL를 불러와서 관련 정보를 test_valiable01 에 넣어 줌.
test_valiable01 = requests.get(internet_Url01)
# 관련 데이터가 잘 들어갔는지 확인하기 위해, print 로 출력함.
print(test_valiable01)
==================================================================================
- 위 코드를 실행을 시켜보면 아래와 같은 출력값이 출력이 됩니다. 여기에서 "<Response [200]>" 은 requests의 응답의 한 종류로서, 현재 지정한 URL에서 Data를 잘 불러와서 입력했다라고 이해하시면 됩니다.
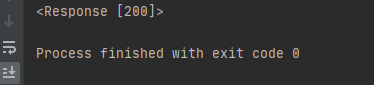
- 그런데 만약, test_valiable01 에 들어있는 Data를 확인하고 싶을 때는 아래 코드를 통해서 확인 하실 수 있습니다.
==================================================================================
# "text" value를 이용하여 관련 내용을 출력함.
print(test_valiable01.text)
==================================================================================
- 위 코드를 실행 시켜보면 엄청나게 많은 데이터가 출력이 되는 걸 확인 하실 수 있습니다. 다 보여 드리지는 못하고, 일부분만 아래와 같이 snap shot으로 첨부 드립니다. 참조하시면 됩니다.
2. 크롤링 기초 - requests 이해 하기 (POST Moduel)
: 그럼 GET 모듈에 대해서 알아 봤으니, login과 관련된 POST 모듈에 대해서도 설명 드리도록 하겠습니다. 이 부분은 login 관련된 내용이니까, 아래와 같은 창까지 접속을 하셔야 합니다.

- 위 화면까지 접속하시고 나서, 개발자 도구를 실행을 합니다. 그리고 나서, 맞지 않은 무작위 아이디나 비밀번호를 입력을 합니다. 그러면 개발자 도구에서 입력된 정보를 기준으로 웹페이지에 표현되는 데이터를 보여주게 됩니다. 그 중 login 관련 항목을 선택하면, login 관련된 내용을 확인 하실 수 있습니다. 아래 사각 박스로 표현되어 있는 "Request Method" 를 보시면, POST 로 표현이 되어 있는 걸 확인 하실 수 있습니다. 즉, 이 호출은 POST 호출이기에 이렇게 표시가 되어 나타나게 됩니다. 그 위에 있는 URL을 이용해서, 크롤링을 진행하려고 합니다.
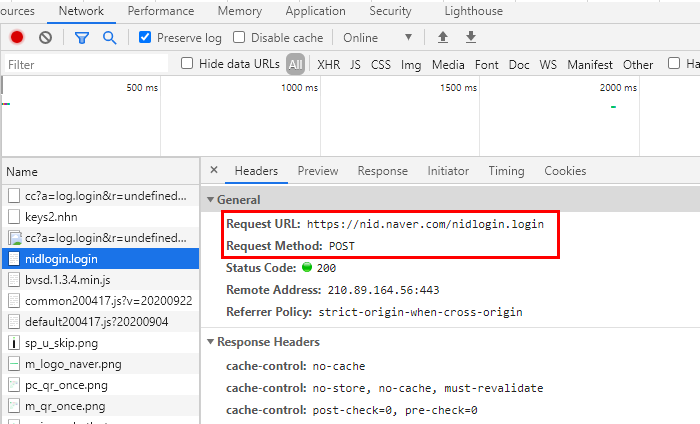
- 위 접수한 URL을 이용하여, 아래와 같은 코드를 구현을 하실 수 있습니다. 위 GET 모듈과 다른 점은, login information을 받는 다는 것입니다. 일단 GET 모듈은 정보만 받는 거지만, POST 모듈은 우리가 어떤 정보를 얻기 위해서 login information을 입력해야 하기 때문입니다.
==================================================================================
# requests 라이브러리를 선언을 함
import requests
# 접속하여, 정보를 가지고 오고 싶어하는 URL을 internet_Url01 에 입력함.
internet_Url01 = "https://nid.naver.com/nidlogin.login"
login_inform = {
"id" : "네이버 ID",
"pw" : "네이버 비밀번호"
}
# requests.get 모듈을 이용하여, internet_Url01에 입력된 URL를 불러와서 관련 정보를 test_valiable01 에 넣어 줌.
test_valiable01 = requests.post(internet_Url01,login_inform )
# 관련 데이터가 잘 들어갔는지 확인하기 위해, print 로 출력함.
print(test_valiable01)
print(test_valiable01.text)
==================================================================================
- 위 코드를 실행을 해보면 위에서 GET 모듈과 같이 많은 양의 데이터가 보여주는 걸 확인 하실 수 있습니다. 그런데, 그 중에 중간 정도에 보시면, 아래와 같은 문구를 확인 하실 수 있습니다. 제가 개인적으로 경험하기로는 네이버는 크롤링을 허용하지 않은 거 같습니다. 제가 말씀드리는 것은 자동로그인을 위한 크롤링을 말씀드리는 것입니다. 시스템적인 매크로 (반복 작업)을 통해서 서버의 과부화를 막으려는 의도라고 생각합니다. 다른 웹사이트를 통해서 테스트 해보시는 걸 추천 드립니다.
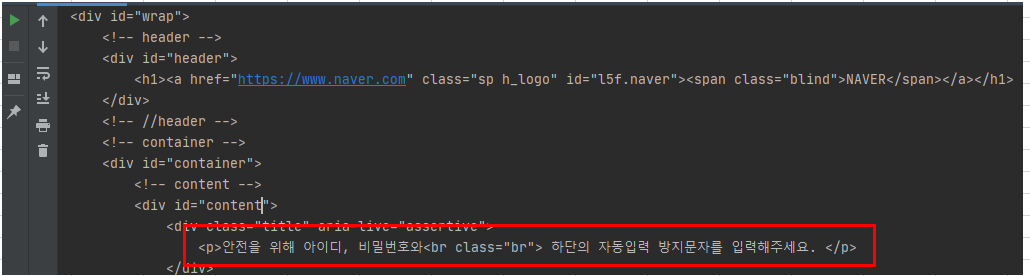
3. 크롤링 기초 - requests 의 헤더(Headers) & Status Code 이해 하기
: 1, 2번 항목을 통해서 GET, POST 모듈에 대해서 알아 봤고, 세부항목으로 Headers & Status Code를 설명해 드리도록 하겠습니다. 간혹, URL을 통해서 크롤링이 잘 되지 않는 경우가 종종 있습니다. 그럴 경우에 사용하는 Information이 헤어(Headers) 라는 속성 값입니다. 그리고 현재 응답코드를 확인하고 싶으면, 아까 처럼 그냥 데이터 수신 받는 변수를 print로 해서 출력할 수 도 있지만, Status Code를 통해서 현재 reqeusts 응답 코드를 확인 하실 수 있습니다. 위에 구현한 코드를 이용하여 보여 드리도록 하겠습니다.
- 일단 네이버에 접속하시고, 개발자 도구를 실행 시킵니다. 그럼 원하는 항목을 선택하시면, 아래와 같이 "Request Headers" 쪽에 명시되어 있는 정보들을 확인 하실 수 있습니다. 이 부분 중에 "User Agent" 항목을 이용하여 구현해보도록 하겠습니다.
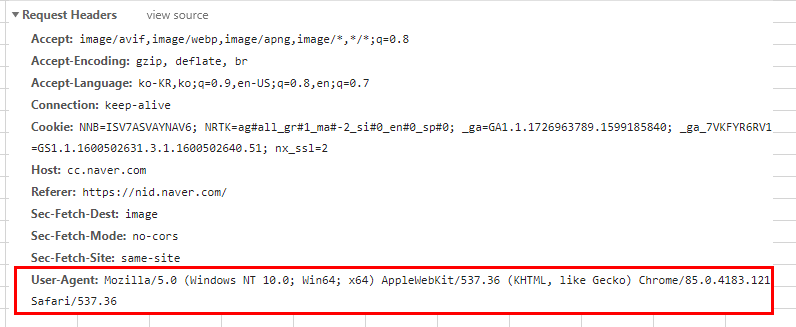
==================================================================================
# requests 라이브러리를 선언을 함
import requests
# 접속하여, 정보를 가지고 오고 싶어하는 URL을 internet_Url01 에 입력함.
internet_Url01 = "https://www.naver.com/"
# headers Information을 가져 올 딕셔너리 변수 "TEST_Headers " 를 선언하여, User-Agent 항목을 입력 해줌.
TEST_Headers = {
'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
# requests.get 모듈을 이용하여, internet_Url01에 입력된 URL를 불러와서 관련 정보를 test_valiable01 에 넣어 줌.
추가적으로 headers value도 추가적으로 고려함.
test_valiable01 = requests.get(internet_Url01, headers = TEST_Headers )
# 관련 데이터가 잘 들어갔는지 확인하기 위해, print 로 출력함.
print(test_valiable01)
print(test_valiable01.text)
==================================================================================
- 위 코드를 실행을 시켜보면 아래와 같이 1번 항목에서 실행 시킨 것과 같이 데이터가 출력이 되는 것을 확인 하실 수 있습니다. 이런 headers information은 URL Information도 크롤링이 안 될 경우에 추가적으로 사용하시는 걸로 일단 인지하시면 될 거 같습니다.
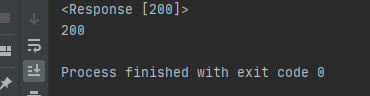
- 그리고 마지막으로 Status Code 는 아래 코드를 추가적으로 첨부해주시면 출력을 보실 수 있습니다. 아래 snap shot을 보시면 print로 그냥 그 변수를 출력하는 것과 Status_code value 를 이용해서 확인 코드를 출력하는 것 둘 다 확인 하실 수 있습니다.
==================================================================================
# 관련 데이터가 잘 들어갔는지 확인하기 위해, print 로 출력함.
print(test_valiable01)
print(test_valiable01.status_code)
==================================================================================
이상입니다. 이번 포스팅은 크롤링에서 정말 필수적으로 사용하는 requests 라이브러리를 중심적으로 알아봤습니다. 일단 requests 라이브러리를 사용하는 것은 알았지만, GET, POST 모듈이 어떤 Base를 기반으로 이용하는지에 대해서 더 알아가는 기회가 되었던 거 같습니다.
그리고 크롤링을 사용하는 사용자는 엄청 편하지만, 그로 인한, 사이트 과부하 등으로 정작 홈페이지를 관리하시는 분들에게는 또 다른 고민거리가 될 수도 있을 거라는 느낌도 받았습니다. 나중에 웹사이트를 오픈할 때 이 부분도 고려해서 할 거 같습니다. 정말 쉬운 게 하나도 없는 거 같습니다. 이 사소한 것도 챙기고, 그것을 무리 없이 구현하는게 정말 능력자가 아닐까 라는 생각을 하게 됩니다. 우리가 같이 공부 열심히 해서 모두 다 그런 능력자가 되시죠. 오늘도 공부하느라고 너무나도 수고 하셨구요, 항상 말씀드리지만, 같이 성장하시죠! 감사합니다.
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁 드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치 하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]
'HTML & CSS' 카테고리의 다른 글
| HTML (Hyper Text Markup Language) 의 정의 및 HTML 태그, W3 (0) | 2021.03.02 |
|---|---|
| 웹페이지 크롤링 + re 정규 표현식을 이용하여 조건 속성 값 정의 하기 (0) | 2021.03.01 |
| 웹 페이지 기본 지식 이해하기 - HTTP (Hyper Text Transfer Protocol) 과 웹페이지 호출 Method GET & POST (0) | 2021.02.20 |
| BeautifulSoup 패키지를 이용해서 HTML 내용 가져오기 (14) | 2021.02.13 |
| 웹 페이지 크롤링 작업 수행 위한 기초 지식 이해하기 - OPEN API 이용하기 (4) | 2021.02.13 |




댓글