안녕하십니까, Davey입니다. 오늘 포스팅할 내용은, 크롤링 할 때 id와 class를 이용하여, 원하는 Data를 추출하는 법에 대한 내용입니다. 이전에 requests, BeautifulSoup에 대한 포스팅을 안보고 오셧다면, 아래 Link를 통해서 먼저 보고 오시는게 더 이해가 빠르실 거라고 생각합니다.
그럼 아래 Link를 통해서 설명 드린 내용은 인지하고 있다라는 전제로, 설명 드리도록 하겠습니다.
1. 웹 페이지 크롤링 작업 수행 위한 기초 지식 이해하기 - OPEN API 이용하기
2. BeautifulSoup 패키지를 이용해서 HTML 내용 가져오기

1. 크롤링을 하고자 하는 웹사이트를 선정하기.
: 일단 크롤링을 하고자 하는 웹사이트를 선정을 하셔야 합니다. 저는 요즘에는 2차 전지에 대해서 관심이 높아지니 2차 전지에 대해서 검색 후 검색 결과로 나온 웹사이트 하나를 가지고 Demostration 해보도록 하겠습니다. 검색해서 선정한 웹사이트의 URL는 아래와 같습니다.
- www.asiae.co.kr/article/2020101001220363691
[금융에세이]"내년 2차전지·정보서비스업 활황 예상"
내년 우리나라 경제는 IT와 장비 업종과 정보서비스업, 반도체 업황이 좋아질 것이라고 전망됐다. 하나금융경영연구소는 최근 ‘2021년 산업 전망’을 발표하고 ‘포스트 코로나 시대의 한국 산�
www.asiae.co.kr
2. 크롤링을 위한 코드 구현
: 웹사이트를 선정하였다면, 이제는 크롤링을 할 수 있는 코드를 구현해야합니다. 제가 사용할 패키지는 이미 예상하셨겠지만, requests 와 BeautifulSoup 입니다. 그럼 패키지 선언 및 관련 코드는 구현하면서 Line by Line으로 설명 드리도록 하겠습니다.
1) 웹사이트 연결 및 BeautifulSoup을 이용하여, 파싱(parsing)하기
==================================================================================
# request, BeautifulSoup 패키지 선언하기
import requests
from bs4 import BeautifulSoup
# 희망하는 URL을 변수에 집어 넣고, 연결시키기
Targeted_URL = 'https://www.asiae.co.kr/article/2020101001220363691'
Requested01 = requests.get(Targeted_URL)
# BeautifulSoup을 이용하여, 파싱(parsing)하기
test_1 = BeautifulSoup(Requested01.text, 'html.parser')
print(test_1)
==================================================================================
- 위 코드를 실행 시켜 보면, 웹사이트 연결이 잘 되었고, 그 관련 내용을 BeautifulSoup을 이용하여, 파싱(parsing)이 성공적으로 이뤄진 것을 확인 할 수 있습니다.

2) 원하는 Information 위치 및 관련 내용 보기
: HTML 문서상, 즉 Web 페이지 상에 원하는 내용이 어디에 소속이 되어 있는지를 알기 위해서는 개발자 도구를 사용하여야 합니다. 크롬에서, 맨 오른쪽에 보면, "..." 을 세로로 표현한 메뉴 버튼이 있는데, 여기에 들어가면, "도구 더보기" 가 있고, 그 하위 속성에, "개발자 도구" 가 있습니다. 이걸 클릭하면, 아래와 같은 창이 나오게 됩니다.
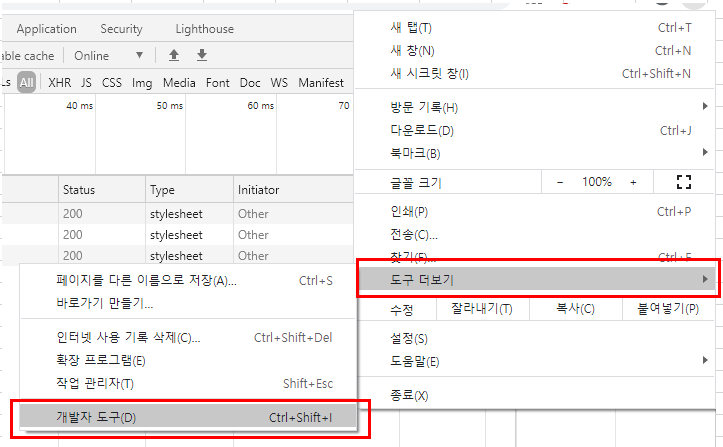
- 오른쪽에, "개발자 도구" 창이 활성화가 되고, 아래 마이스 커서 모양의 메뉴를 선택하여, 원하는 내용을 클릭하게 되면, 그 해당하는 항목에 검색이 됩니다. 정말 편리한 기능입니다.

3) 내용 크롤링을 위한 코드구현하기
: 1,2번 항목에 설명 드린 내용을 기반으로 원하는 내용의 위치를 파악하고, id, class의 information을 알아 내셨다면, 이제는 그 해당 내용을 추출할 수 있는 코드를 구현해보도록 하겠습니다. 이해를 돕기 위해서, 위에 구현한 코드와 함께 설명 드리도록 하겠습니다.
==================================================================================
# request, BeautifulSoup 패키지 선언하기
import requests
from bs4 import BeautifulSoup
# 희망하는 URL을 변수에 집어 넣고, 연결시키기
Targeted_URL = 'https://www.asiae.co.kr/article/2020101001220363691'
Requested01 = requests.get(Targeted_URL)
# BeautifulSoup을 이용하여, 파싱(parsing)하기
test_1 = BeautifulSoup(Requested01.text, 'html.parser')
# class 속성 값을 이용하여 Data 추출하기
result01_class01 = test_1.find('div', class_ ='area_title')
result01_class02 = result01_class01.find('h3')
print(result01_class02.get_text().strip())

# 한 줄 띄우기
print()
# id 속성 값을 이용하여 Data 추출하기
result01_id1 = test_1.find('div', id='txt_area')
result01_id2 = result01_id1.find('p')
print(result01_id2.get_text().strip())

==================================================================================
- 위 코드를 실행을 시켜보면 아래와 같이 원하는 항목에 대한 속성값이 추출이 되는 걸 확인 하실 수 있습니다.

이상입니다. 일단 원하는 웹사이트의 연결을 성공시키면, 그 안에 내용 중에 원하는 항목에 대한 추출 코드를 구현을 해야 합니다. 그런데, 원하는 id와 class를 찾는 것도 조금의 노력이 필요하다는 것도 인지하셔야 합니다. 위에 구현하는 코드는 원하는 id와 class를 찾는 노력을 필수적으로 필요한 사항이라는 점 감안하시고, 코드를 구현하셔야 합니다. 좀 까다롭고, 찾는 데 시간이 좀 걸리겠지만, 그런 노력만 한다면 구현이 되는 라이브러리와 패키지가 있다는 게 저는 너무나도 감사하다는 생각이 듭니다. 나중에 제가 성장한다면, 이런 도움이 되는 패키지를 만들 수 있는 사람이 되고 싶습니다. 그럼 이만 마무리 하도록 하겠습니다. 같이 공부하고, 같이 성장하시죠! 감사합니다.
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁 드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치 하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]
'HTML & CSS' 카테고리의 다른 글
| 웹 페이지 크롤링 작업 수행 위한 기초 지식 이해하기 - requests 라이브러리 (0) | 2021.02.27 |
|---|---|
| 웹 페이지 기본 지식 이해하기 - HTTP (Hyper Text Transfer Protocol) 과 웹페이지 호출 Method GET & POST (0) | 2021.02.20 |
| BeautifulSoup 패키지를 이용해서 HTML 내용 가져오기 (14) | 2021.02.13 |
| 웹 페이지 크롤링 작업 수행 위한 기초 지식 이해하기 - OPEN API 이용하기 (4) | 2021.02.13 |
| 웹페이지 크롤링 + CSS 메소드를 이용하여 원하는 Data 추출 하기 (17) | 2021.02.13 |




댓글