안녕하세요, Davey입니다. 이번에 포스팅할 내용은, 요즘 핫한 주식 관련 프로그램 (예명 "You Know Stock")에 대해서 설명을 드리려고 합니다. 이전에 며칠 주가를 이용하여, 그 며칠 주가 다음 날의 주가를 예측하는 프로그램입니다.

저도, 이번에 머신러닝과 딥러닝을 공부하면서, 이것 저것 찾아보면 공부한 내용입니다. 그럼 제가 나름대로 공부하고 분석한 내용을 기반으로 아래와 같이 자세히 설명드리도록 하겠습니다.
'You Know Stock' 프로그램을 위한 Python 라이브러리
: "You Know Stock" 프로그램을 위해서 아래와 같은 라이브러리가 필요하며, 설명과 같이 선언도 같이 동시에 진행하도록 하겠습니다.
=================================================================
# 어떤 Dataset을 읽어 오기 위한 라이브러리
import pandas as pd
# 어떤 Dataset을 List화 하고, 원하는 Data 배열으로 Modification을 하기 위한 라이브러리
import numpy as np
# 분석한 값과, 출력 값을 비교하기 위해, 그래프 화 하기 위해서 필요한 라이브러리
import matplotlib.pyplot as plt
# 기존 데이터를 Training 시키고, 이후 TEST 까지 하기 위한 라이브러리
from keras.models import Sequential
from keras.layers import LSTM, Dropout, Dense, Activation=================================================================
- 위 내용과 추가적으로 LSTM에 대해서 간단하게 설명 드리도록 하겠습니다. LSTM은 한국어로, 롱 단기 메모리(LSTM)라고 하며, 딥러닝 분야에서 사용되는 인공 재발 신경망(RNN) 아키텍처입니다. 표준 피드 포워드 신경망과 달리 LSTM은 피드백 연결이 있다. 단일 데이터 지점(이미지 등)뿐만 아니라 전체 데이터 시퀀스(예: 음성 또는 비디오)를 처리할 수 있습니다. 예를 들어 LSTM은 분할되지 않은 연결된 필기 인식, 음성 인식 및 네트워크 트래픽이나 IDS(내부 감지 시스템)에서의 이상 감지와 같은 작업에 적용할 수 있습니다.
공통 LSTM 장치는 셀, 입력 게이트, 출력 게이트 및 기억 게이트로 구성되며, 셀은 임의의 시간 간격에 걸쳐 값을 기억하며, 세 개의 관문은 셀로 들어오고 나가는 정보의 흐름을 조절합니다.
LSTM 네트워크는 시계열 데이터의 분류, 처리 및 예측에 유용합니다. 시계열에서 중요한 사건 사이에 알 수 없는 지속시간의 시차가 있을 수 있기 때문입니다. LSTM은 기존의 RNN을 훈련할 때 발생할 수 있는 소실 구배 문제를 해결하기 위해 개발되었습니다.. 갭 길이에 대한 상대적 불감증은 RNN, 숨겨진 마르코프 모델 및 기타 시퀀스 학습 방법들에 비해 LSTM의 장점입니다.
[참조 자료 : en.wikipedia.org/wiki/Long_short-term_memory]
'You Know Stock' 프로그램을 구현하기 위한 Souce Data 얻어오기
: 주식 관련 내용이 이기 때문에, 주식 차트 기록을 가져 와야 합니다. 여러 사이트가 있지만, 아래 사이트 추천드립니다. 네이버나, 다른 사이트에서 받으려고 하니까, 약간 복잡하더라고요. 혹시, 더 좋은 사이트 아시는 분 계시면, 알려주시면(댓글로), 감사드리겠습니다.
- Yahoo Finace 자료 ( www.yahoo.com/)
: 관련 Link에 들어가서, "Finance" 항목을 클릭하면 경제 관련 웹페이지로 이동을 합니다.

- 그리고 나서, 검색 창에 자신이 자료를 얻고 싶어 하는 종목을 입력하여 조회를 하시면 됩니다. 저는 예시로, 요즘에 핫한, "SK 바이오팜"으로 하도록 하겠습니다. 영어로는, SK Bioparmaceuticals라고 입력하시면 됩니다. 그리고 아래 표시해둔, Historical Data 항목을 클릭하고

- Historical Data에서 원하는 기간을 설정을 해주시고, Download를 받아 주시면, 끝입니다.
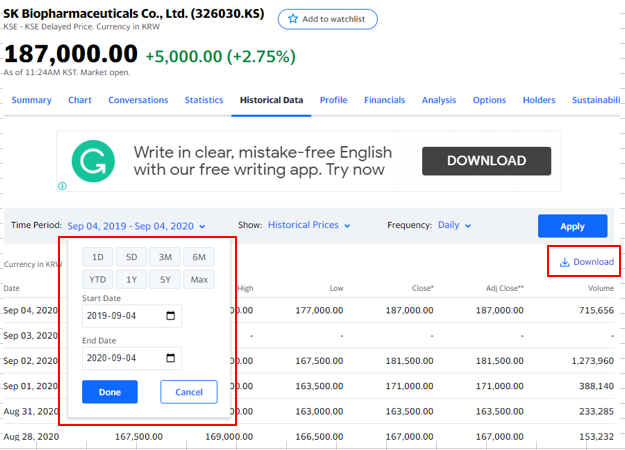
- 다운 받은 파일은, Code 파일이 위치한 폴더에 넣어 주시면 됩니다.

3. "You Know Stock" 프로그램을 Code 구현하기
: 이제 Source Data도 다 받아왔으니까, Code를 구현해보도록 하겠습니다. 위 1번에서 말씀드린 라이브러리도 같이 해서 코드 구현하도록 하겠습니다.
=================================================================================
# 라이브러리 설명은 위 1번 항목 참조 부탁 드립니다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import LSTM, Dropout, Dense, Activation
Source_Data = pd.read_csv('./skbioparm01.csv')
print(Source_Data)=================================================================================
- 위 코드를 실행시켜 보면, 아래와 같이 file의 Data를 읽어 오는 걸 확인하실 수 있습니다. 1년 치를 했지만, 상장한 지 별로 안돼서, 데이터는 별로 없습니다. 즉, 훈련시킬 데이터가 작다는 거죠. 나중에 보시면 아시겠지만, 훈련시킨 데이터의 양도 이 머신러닝과 딥러닝에 정말 중요한 포인트입니다.
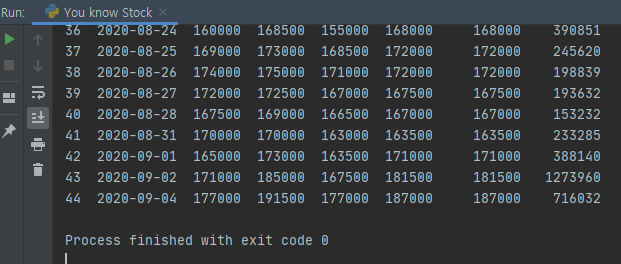
- 위 내용이 잘 작동하는 걸 확인하셨으면 실제로, 데이터를 Modification 해 보록 하겠습니다. 일단, 가장 높은 값과, 낮은 값에 대한 중간 값 그리고, 그 중간 값을 첫 번째 값으로 나눠주면서, 동일 시 시키는 작업을 해보도록 하겠습니다.
=================================================================================
High_Column_Value = Source_Data ['High']. values # "High" Column에 있는 Data
Low_Column_Value = Source_Data ['Low']. values # "Low" Column에 있는 Data
Middle_Value = (High_Column_Value + Low_Column_Value) / 2 # "High", "Low" 값의 중간 값 출력
Data_Range01 = 5 # 테스트를 한 데이터 Range 값
Data_Range02 = Data_Range01 + 1 # 테스트를 한 데이터 Range 값의 다음 값에 대한 인수 값
print(len(Middle_Value) - Data_Range02) # 당연히 44-6 = 38 이 됨.
-> 이렇게 중간중간의 값 확인을 위해, print를 자주 사용해서 확인하셔야 합니다.=================================================================================
- 자, 위 항목에서 출력 값을 확인하셨으면, 첫 번째 값(기준값)을 이용해서, 데이터를 정량화시켜 보도록 하겠습니다. 그리고, 그 정령화 된 데이터로 훈련 및 테스트 후, 그래프로 비교한 값 내용을 출력해보도록 하겠습니다. 학습시키는 양이 적기 때문에, 일단 학습 시키는 양을 좀 줄여서 해보도록 하겠습니다.
=================================================================================
# 앞에 설정한 개수만큼 데이터를 담을 List를 하나 선언함
arrange01 = []
# 아래 print 관련 code 중간중간 값을 확인하기 위한 code 이므로, 활용하시면 됨.
for index in range(len(Middle_Value) - Data_Range02):
# print(index + Data_Range02)
# print('================================')
# print([index: index + Data_Range02])
# print('================================')
# print(Middle_Value [index: index + Data_Range02])
arrange01.append(Middle_Value [index: index+Data_Range02])
# 아래 print 관련 code 중간중간 값을 확인하기 위한 code 이므로, 활용하시면 됨.
print(Middle_Value)
print(arrange01)
# 정량화 한 값을 닮을 List를 하나 선언함
arrange02 = []
for item in arrange01:
arrange02_window = [((float(p) / float(item [0])) - 1) for p in item]
arrange02.append(arrange02_window)
Final_Verification01 = np.array(arrange02)
# 아래 print 관련 code 중간중간 값을 확인하기 위한 code 이므로, 활용하시면 됨.
# print(arrange02.shape)
# 90%로 훈련을 시킬 예정, 10%를 가지고 검증 할 예정
row = int(round(Final_Verification01.shape [0] * 0.9))
# 아래 print 관련 code 중간중간 값을 확인하기 위한 code 이므로, 활용하시면 됨.
# print(result [:row,:])
train = Final_Verification01 [:row, :]
# 섞어줘야지, 더 신뢰성이 있는 Data 출력이 나옴.
np.random.shuffle(train)
x_train = train [:, :-1]
x_train = np.reshape(x_train, (x_train.shape [0], x_train.shape [1], 1))
y_train = train [:, -1]
x_test = Final_Verification01 [row:, :-1]
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
y_test = Final_Verification01[row:, -1]
print(x_train.shape, x_test.shape)
print(y_train)
print(y_test)
# Sequential() Method를 사용
model = Sequential()
# LSTM 원리를 이용
model.add(LSTM(5, return_sequences=True, input_shape=(5, 1)))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(1, activation='linear'))
model.compile(loss='mse', optimizer='rmsprop')
# batch_size=1 <- 1개의 데이터 값을, epochs=50 <- 50번 훈련 시킨다는 뜻
model.fit(x_train, y_train,
validation_data=(x_test, y_test),
batch_size=1,
epochs=50)
pred = model.predict(x_test)
# 훈련된 기계를 통해, 나온 데이터를 보기 위한 code
print(pred)
# TEST를 활용한 데이터와 x_text 값에 따른, 머신 출력값을 보고 비교하기 위해 그래프를 출력하기 위한 code
fig = plt.figure(facecolor='white', figsize=(20, 10))
ax = fig.add_subplot(111)
ax.plot(y_test, label='Original Data')
ax.plot(pred, label='Predicating Data')
ax.legend()
plt.show()
======================================================================
- 위 코드를 실행을 해보면, 아래와 같은 데이터를 출력할 수 있습니다. 기존 테스트 값에 비해, 초반에는 얼추 맞는 거 같은데, 후반에는 정말 틀린 값이 나오는 걸 보실 수 있습니다.

- 하지만 아래 그림은, 삼성전자 (데이터 양이 많음)로 돌렸을 때는 나오는 그림입니다. 오차는 당연히 있지만, 그래도 어느 정도는 대략 비슷한 그림이 나오는 걸 확인하실 수 있습니다.

- 즉, 1번째 그림과 2번째 그림을 보시면, 왜 정량화된 데이터 값이 많이야 되는지를 이해하실 수 있습니다. 그래서 사람들이 그렇게 빅데이터가 필요하다고 얘기를 하는 겁니다.
이상입니다. 저도 처음에는 이런 내용을 이해하는데 너무나도 오래 걸렸습니다. 하나하나 print code를 써 가면서, 결과 값을 보고, 그 결과 값을 분석해서, 왜 이게 나오는지를 확인하는 과정을 거쳤습니다. 그리고 기존에 참고했는 코드와 별개로, 결과 값을 보는 코드를 써가면서, 작업을 했습니다. (이 부분은 제가 더 해보고 공유드리도록 하겠습니다.) 여러 케이스를 가지고 검증을 하고 있으며, 나름대로 신뢰성 있는 Study 자료가 나오면 추가 포스팅하도록 하겠습니다. 항상 공부 열심히 하시고, 같이 성장하시죠. 감사합니다.
참고자료
: www.youtube.com/watch?v=sG_WeGbZ9A4&list=PL-xmlFOn6TULrmwkXjRCDAas0ixd_NtyK&index=39&t=628s
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁드립니다. 검토 후 수정 및 삭제 조치하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을 때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]




댓글