안녕하세요, 오늘 포스팅할 내용은 scikit-learn이라는 패키지 입니다. Scikit-learn에 대해서 우선 먼저 설명 드리도록 하겠습니다. 머신러닝을 위한 모델링 작업 중 하나의 방식이라고 생각하시면 됩니다.

지난 번에 포스팅한 선형회귀 모델링 속편이라고 생각하시면 됩니다. 그때는, 식을 하나 하나 풀어서, 설명을 하고 코드를 작성을 하였지만, 이번에는 좀 더 손쉽게 구현할 수 있는 파이썬 라이브러리를 이용하여 구현해보도록 하겠습니다. 이전 포스팅을 먼저 공부하지 않으신 분들은 아래 링크 통해서 먼저 공부하시는 걸 추천 드리겠습니다.
Scikit-learn 라이브러리
: Scikit-learn(이전의 Scikits.learn, 일명 sklearn)은 Python 프로그래밍 언어를 위한 무료 소프트웨어 머신러닝 라이브러리입니다. 지원 벡터 머신, 랜덤 포리스트, 그라데이션 부스팅, k-평균, DBSCAN 등 다양한 분류, 회귀, 클러스터링 알고리즘이 특징이며, 파이썬 수치 및 과학 라이브러리 NumPy, SciPy와 상호운용되도록 설계되었습니다.
- 이 Scikit-learn 프로젝트는 데이비드 쿠르나포의 Google Summer of Code 프로젝트인 Scikits.learn에서 시작되었습니다. 이 명칭은 별도로 개발, 배포한 제3자 증설인 'SciKit'(SciPy Toolkit)라는 개념에서 유래했으며, 원래의 코드베이스는 나중에 다른 개발자들에 의해 다시 작성되었습니다. 2010년 프랑스 록켄코트에 있는 프랑스 컴퓨터과학자동화연구소의 파비안 페드레고사, 가엘 바로코, 알렉산드르 그램포트, 빈센트 미셸이 모두 이 프로젝트를 주도하여 2010년 2월 1일 첫 공개하였습니다. Scikit-Learn은 GitHub에서 가장 인기 있는 기계 학습 라이브러리 중 하나이다.
- Scikit-learn은 주로 Python으로 작성되며, 고성능 선형 대수학 및 배열 연산을 위해 numpy를 광범위하게 사용합니다. 즉, Scikit-learn을 구현하기 위해서 numpy를 많이 사용한다라고 이해하시면 됩니다.
- Scikit-Learn은 배열 벡터화를 위한 numpy 뿐만 아니라, matplotlib 및 플롯, 팬더 데이터프레임, scipy 등과 같이 구현을 하고 있습니다.
[참고 자료 : en.wikipedia.org/wiki/Scikit-learn]
Scikit-learn 라이브러리 설치하기
: Scikit-learn 라이브러리를 구현하기 위해서, 일단 라이브러리를 설치를 하여야 합니다. 설치 구문은 아래와 같습니다.
-> pip install Scikit-learn
- 위 구문을 입력을 하면, 설치가 되는 Progress 창이 나오면, 설치가 완료가 되면, "sucessfully installed" 라고 문구가 나옵니다. 저는 이미 설치가 완료된 상태라 아래와 같은 구문이 나옵니다. (기 설치한 분들은 설치 안하셔도 됩니다.)

선형 회귀 모델링 코드 구현하기
: 위에 공유 드린 Link를 통해 들어가보시면, 코드 길이가 나열이 되어 있는 것을 확인 하실 수 있습니다. 왜냐하면, 수학적인 계산식까지 일일히 나열했으며, 제가 이해한 부분을 또 추가해서 설명을 드리는 과정에서 코드가 좀 길어졌습니다. 하지만 Scikit-learn을 이용하면, 상대적으로 간단하게 구현이 가능합니다.
1) 라이브러리 선언하기
: 선현 회귀 모델링을 Scikit-learn 패키지를 이용하여, 구현하기 위해서 아래 라이브러리를 설치 및 선언을 해야합니다.
==================================================================================
# 배열화 시키기 위한 라이브러리 numpy 입력
import numpy as np
# Scikit-learn 패키지 중에 LinearRegression 모델 입력
from sklearn.linear_model import LinearRegression
# 입력 및 출력 값을 그래프화 하기 위해서, matplotlib 입력
import matplotlib.pyplot as plt
==================================================================================
2) 임의의 Initial 값을 랜덤하게 선언하기.
: 선현 회귀 모델링를 구현하기 위해서, 초기 값을 선언을 하는데, 하나 하나 입력하지 않고, 랜덤하게, 임의의 수식을 통해서, 선언을 할 예정입니다.
==================================================================================
# Initial Data를 초기에 선언할 List 변수를 두개를 선언
resource01 = []
resource02 = []
# For 문을 이용하여, 임의 수식을 통해서, List에 속성값을 추가 시킴.
for i in range(10):
resource01.append(1 + i + (i + 1)/10)
resource02.append(2 + i**2 + (i + 2)/10)
# List의 속성값을 numpy를 통해서 배열화 시킴.
resource01_mod = np.array(resource01)
resource02_mod = np.array(resource02)
# 배열된 값을 확인하기 위해서, 아래와 같이 print 를 사용.
print(resource01_mod)
print(resource02_mod)
==================================================================================
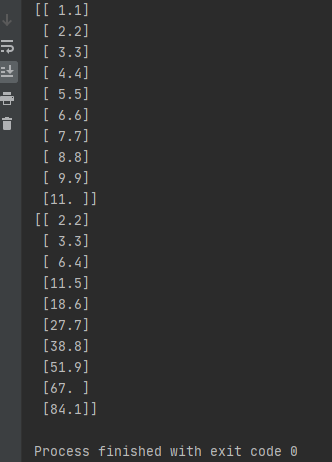
- 위 코드를 구현을 해보면, 아래와 같은 결과값이 출력되는 걸 확인 하실 수 있습니다. 즉, 랜덤하게 값이 입력이 되었고, 그 값들이 numpy를 통해서 배열화 되어 출력이 되는 걸로 이해하시면 됩니다.

- 이제 이 배열한 속성값을 모델링 작업을 위한 형태로 변경을 해줘야 합니다. 여기에서 사용할 메소드는 reshape 입니다. 이전 포스팅에서 설명 드렸듯이, n x 1 행렬 형태로 형태를 변경해주셔야 합니다.
==================================================================================
# numpy로 배열화 한 속성값의 배열 형태를 n x 1 형태로 변경을 해줍니다.
test_data1 = resource01_mod.reshape(-1,1) # 몇개의 행인지를 계산하기 싫을 때는, "-1"을 이용해도 무방하다.
test_data2 = resource02_mod.reshape(-1,1) # 몇개의 행인지를 계산하기 싫을 때는, "-1"을 이용해도 무방하다.
==================================================================================
- 위 코드를 실행을 해보면 아래와 같은 결과값이 출력됩니다. 즉, 배열된 개수 = 행의 개수가 되고, 1열로 재 배열이 된 걸 확인 하실 수 있습니다.
- 이제 reshape를 통해서 재배열된 배열 값을 LinearRegression() 모듈을 통해서, 모델링 작업을 해보도록 하겠습니다. 아래 코드 참조 부탁 드립니다.
==================================================================================
# Linear Regression Verification (y_model = a*test_data1 +b)을 위해 LinearRegression() 모듈을 사용
F_model = LinearRegression()
# test_data1 은 X 의 값, test_data2 은 Y 값이라고 인지하시면 됩니다.
F_model.fit(test_data1, test_data2)
Model1 = F_model.intercept_ + F_model.coef_*test_data1
print('Constant Value:', F_model.intercept_) # LinearRegression() 모듈을 통해 얻은 b 상수 값
print('Gradient Value:', F_model.coef_) # LinearRegression() 모듈을 통해 얻은 a 기울기 값
print('Modeling Value:', Model1) # a, b가 적용된 모델링 출력 값
==================================================================================
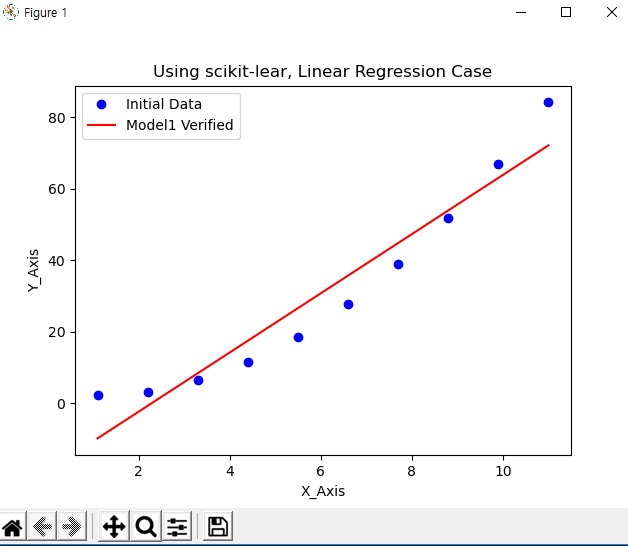
- 이제 모델링 까지 마쳤으니, Initial Data와 비교하여, 모델링한 식이 얼마나 정확도가 높은지에 대해서, 확인 작업을 하도록하게습니다. 하나 하나 수치로 계산을 하는 것보다 시각적으로 쉽고 빠르게 확인 할 수 있는 그래프를 통해서 확인하도록 하겠습니다.
==================================================================================
# 위에 분석한 내용을 시각적으로 쉽고 빠르게 확인 할 수 있는 그래프로 구현함.
plt.figure(1)
plt.plot(test_data1,test_data2, 'bo', label='Initial Data') # Initial Data를 점으로 표현을 함.
plt.plot(test_data1,Model1, 'r-', label='Model1 Verified') # 모델링한 식에, X 값을 대입하여, Linear한 선으로 표현
plt.legend(loc='upper left')
plt.title('Using scikit-lear, Linear Regression Case')
plt.xlabel('X_Axis')
plt.ylabel('Y_Axis')
plt.show()
==================================================================================
- 전체적으로 코드를 실행을 해보면 아래와 같은 그래프를 보실 수 있습니다. 처음 Initial한 값이 약간은 Linear해서, 확인 하시기 수월하실 겁니다. 이렇게, 오차 값을 최소한으로 줄여서, 모델링한 값에 똑같이 X 값을 대입한 모델링 출력값이 나름대로, 잘 나오는 것을 보 실 수 있습니다. 이런 모델링 작업을 Scikit-learn 패키지를 통해서, 정말 간단하게 작업이 가능하다는 것을 확인 하실 수 있습니다.
이상입니다. 지금까지 scikit-learn이라는 패키지에 대해서 포스팅을 작성하였습니다. 정말 수식에 하나 하나 분석해서, 고민해보고, 왜 이렇게 되나 생각해봐서, 이해를 하고 나서 또 돌아서면 까먹고 대충만 감만 알고 있는 날이 지속되다가, 이런 패키지를 만나니까, 한편으로 정말 반갑기도 하고, 한편으로는 이것만 썼다가는 기존에 알고 있는 지식도 다 까먹겠다라는 이중적인 생각이 들었습니다.
하지만 주구장창 그 식만 가지고 있는게 아니고, 그 수식을 이용해서 내가 원하는 값을 얻는 게 최종 목적이기에, 이런 패키지가 있으면 정말 유용할 거라고 생각합니다. 오늘도 공부하시느라고, 정말 수고 많이 하셨고요. 항상 공부하고, 항상 성장하시죠! 감사합니다.
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁 드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치 하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]
'파이썬 (Python) > 딥러닝 (Deep Learning)' 카테고리의 다른 글
| Python 파이썬 머신 러닝(Machine Learning) 기초 - 통계학, 머신 러닝 자료 Type (0) | 2021.03.01 |
|---|---|
| 머신 러닝(Machine Learning) - 선형 회귀 모델링 + Tensorflow 패키지 (1) | 2021.03.01 |
| 머신러닝을 이용한 "You Know Stock" 주식 분석 및 예측 Plot 프로그램 (0) | 2021.02.28 |
| 파이썬 음성을 텍스트로 변환 하고, 내 말에 대답하는 AI 로봇 만들기 + gTTs, SpeechRecognition 라이브러리 (0) | 2021.02.28 |
| 머신 러닝(Machine Learning) - 선형 회귀 모델링 Analystical Solution 사용 방법 (0) | 2021.02.28 |




댓글