안녕하세요, 이번 포스팅도 파이썬을 이용해서 웹사이트 크롤링 하는 방법에 대해서 작성하도록 하겠습니다. 이전 포스팅에서 설명드린 내용과 연관해서 설명 드리도록 하겠습니다.

이전 포스팅에서 사용했던 크롤링 크롤링 Code를 이용하여, 이어서 포스팅 하도록 하겠습니다. 참조하시라고 이전 포스팅에서 사용한 크롤링 코드는 아래 링크를 통해서 확인 하실 수 있습니다.
파이썬 Python 웹사이트 컨텐츠 크롤링하기
안녕하세요, Davey 입니다. 오늘 포스팅 내용은 웹사이트 컨텐츠 크롤링하는 내용입니다. 크롤링을 실제적으로 TEST 및 간단한 코드를 통해서 demostration 해보도록 하겠습니다. 그럼, 일단, crawling을
davey.tistory.com
이전 포스팅을 보지 못하시고 현 포스팅을 보시는 분들은 Beautifulsoup4를 꼭 설치 해주세요. 그래야 크롤링이 가능합니다. 아래 코드를 통해서도 확인하실 수 있을 겁니다.
이전 포스팅에 기재된 Code로 크롤링을 하게 되면, 나중에 Form 작성 하더라도, 한가지 URL에서만 크롤링을 할 수 있습니다. 즉, URL이 고정되어 있는 상태입니다. 그래서, 프로그램의 유연성과 편의성을 위해서, 입력하는 값에 따라서, 크롤링을 자유롭게 하는 code를 작성할 예정입니다.
위 항목에서, 추가적으로 선언할 library는 urlib.parse 입니다. 선언한 code는 아래와 같습니다.
import urllib.request
import urllib.parse # 한글을 ascii 로 변환 해줌
from bs4 import BeautifulSoup
urladdress1 = 'https://search.naver.com/search.naver?where=post&sm=tab_jum&query=%EC%98%81%EC%96%B4%EA%B3%B5%EB%B6%80'
# 검색어를 입력하고 나서 나오는 결과 창의 URL을 받는 변수
htmlcontent1 = urllib.request.urlopen(urladdress1).read()
verification1 = BeautifulSoup(htmlcontent1, 'html.parser')
# urladdress1의 변수에 있는 URL을 이용하여, HTML을 읽어 오는 Code
data1 = verification1.find_all(class_='sh_blog_title')
# 읽어온 HTML에서 필요한 부분에 대한 결과를 얻기 위한 Code
for item in data1: # 각 항목을 다 뿌지리 말고, 그 내용중에 하나 하나 씩 결과물 가져오기 위한 반복문
print(item.attrs['title']) # 속성값 중에 Title 가져오기
print(item.attrs['href']) # 속성값 중에 URL 가져오기
print() # 결과 내용 사이 사이에 빈칸을 두기
위에 항목에서, urladdress1에 기재된 항목을 잘 보면, 맨 뒤에는 알수 없는 기호로 기재가 되어 있는 상태입니다. 이 부분이 ascii 코드입니다. 한글로 검색을 하면, pycharm에서는 ascii로 변환을 한거죠.
한가지 예를 들면, 아래와 같이 Code를 수정하였습니다.
import urllib.request
import urllib.parse # 한글을 ascii 로 변환 해줌
from bs4 import BeautifulSoup
urladdress1 = 'https://search.naver.com/search.naver?where=post&sm=tab_jum&query=프로그램'
# 검색어를 입력하고 나서 나오는 결과 창의 URL을 받는 변수
htmlcontent1 = urllib.request.urlopen(urladdress1).read()
verification1 = BeautifulSoup(htmlcontent1, 'html.parser')
# urladdress1의 변수에 있는 URL을 이용하여, HTML을 읽어 오는 Code
data1 = verification1.find_all(class_='sh_blog_title')
# 읽어온 HTML에서 필요한 부분에 대한 결과를 얻기 위한 Code
for item in data1: # 각 항목을 다 뿌리지 말고, 그 내용중에 하나 하나 씩 결과물 가져오기 위한 반복문
print(item.attrs['title']) # 속성값 중에 Title 가져오기
print(item.attrs['href']) # 속성값 중에 URL 가져오기
print() # 결과 내용 사이 사이에 빈칸을 두기
ascii 코드로 변환된 맨 뒤에 URL 내용을 그냥 네이버에서 나온 대로, 한글을 입력 해보았습니다.
아래 네이버에서 검색한 URL을 그대로 붙은 거라고 생각하시면 됩니다.
위에 보여드린 code를 이볅하면 아래와 같이 Error가 발생하게 됩니다. 위에 긴 error 중에 가장 핵심 error는 아래와 같습니다. 즉, ascii 코드가 변환이 필요하다는 겁니다.
return request.encode('ascii')
UnicodeEncodeError: 'ascii' codec can't encode characters in position 54-57: ordinal not in range(128)

그래서, 코드 변환을 위해서 아래와 같이 코드를 수정해보았습니다.
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
urladdress1 = 'https://search.naver.com/search.naver?where=post&sm=tab_jum&query='
# 검색어를 입력하고 나서 나오는 결과 창의 URL을 받는 변수
urladdress2 = input('검색할 단어를 입력하세요 : ')
위 코드를 실행하면 아래와 같이 결과 값을 볼 수 가 있습니다.
--------------------------------------------------------------------------------------------------
검색할 단어를 입력하세요 :
--------------------------------------------------------------------------------------------------

검색할 단어에, 자신이 찾고 싶은 검색어를 집어 넣으면, 그 검색 창에 해당하는 HTML Code를 가져오게 됩니다.
아래 항목은 일단 주석처리 하였습니다. 일단 위에 나와 있는 Code를 입력하고, 실행을 하면, error가 안뜨고, 정상적으로 작동하는 걸 알수 있습니다. print () 항목을 통해서, error 유무를 확인하는 것도 Tip 입니다.
그럼 그 HTML에서, 필요한 제목과 관련 URL만 가져 오는 항목을 다시 주석처리해서 정리해보겠습니다.
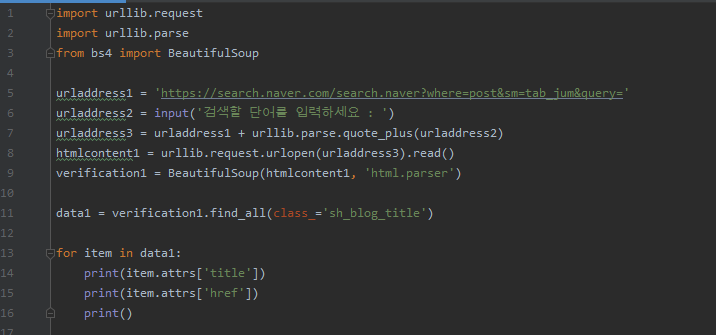
정리된 Code는 아래와 같습니다.
import urllib.request
import urllib.parse # 한글을 ascii 로 변환 해줌
from bs4 import BeautifulSoup
urladdress1 = 'https://search.naver.com/search.naver?where=post&sm=tab_jum&query='
# 검색어를 입력하고 나서 나오는 결과 창의 URL을 받는 변수
urladdress2 = input('검색할 단어를 입력하세요 : ')
urladdress3 = urladdress1 + urllib.parse.quote_plus(urladdress2)
htmlcontent1 = urllib.request.urlopen(urladdress3).read()
verification1 = BeautifulSoup(htmlcontent1, 'html.parser')
# urladdress1의 변수에 있는 URL을 이용하여, HTML을 읽어 오는 Code
data1 = verification1.find_all(class_='sh_blog_title')
# 읽어온 HTML에서 필요한 부분에 대한 결과를 얻기 위한 Code
for item in data1: # 각 항목을 다 뿌지리 말고, 그 내용중에 하나 하나 씩 결과물 가져오기 위한 반복문
print(item.attrs['title']) # 속성값 중에 Title 가져오기
print(item.attrs['href']) # 속성값 중에 URL 가져오기
print() # 결과 내용 사이 사이에 빈칸을 두기
Code를 실행 시켜 보면 아래와 같이 결과값을 얻을 수 있습니다. (검색어 : 프로그램)
C:\Users\Administrator\Anaconda3\envs\Python_Project\python.exe D:/Python_Project/Macro_TEST1.py
검색할 단어를 입력하세요 : 프로그램
캐나다조기유학 메이플리지 교육청 관리형 유학 프로그램 추천
https://blog.naver.com/foodvalue97?Redirect=Log&logNo=221839080278
신내동영어학원 초등영어 개인별 맞춤 프로그램 GLEC
https://blog.naver.com/glec_academy?Redirect=Log&logNo=221886645088
캐나다인턴 프로그램은 GBC어학원
https://bigpinksea.blog.me/221880678345
원격제어프로그램 알서포트 리모트뷰 원격근무 최적
https://blog.naver.com/kimcoco1?Redirect=Log&logNo=221846466498
이미지 번역, 사진 번역에 좋은 크롬 확장 프로그램 Copyfish
https://blog.naver.com/aufcl856?Redirect=Log&logNo=221780576825
슬기로운 집콕생활 : 공부 아닌, 공부 같은 넷플릭스 초등 프로그램 추천
https://blog.naver.com/pholive21?Redirect=Log&logNo=221877824215
동영상 편집 프로그램 Movavi Suite 17 90% 할인 중
https://feena74.blog.me/221885214288
코로나19 극복 정책금융 프로그램 A to Z…1일부터 본격 가동
https://blog.naver.com/mirae_saram?Redirect=Log&logNo=221886630526
상자(박스) 제조업에 특화된 생산관리 프로그램 ERP(맞춤ERP 및 스마트공장지원사업)
https://dutni72.blog.me/221886695942
2020 YIP 청소년 발명가 프로그램
https://blog.naver.com/bosungabi?Redirect=Log&logNo=221845296000
Process finished with exit code 0
그럼 별도의 URL 없이 블로그 항목을 원하는 검색어로 크롤링을 할 수 있게 되는 겁니다.
이상입니다. 지금까지 파이썬으로 별도의 URL 없이 블로그 항목을 원하는 검색어로 크롤링을 할 수 있게 하는 코드에 대해서 설명을 드렸습니다. 위에 설명 드린 사항을 이용해서 자신에게 맞는 code도 개발해보시는 것도 좋을 거라고 생각합니다. 그럼 진짜 눈으로만 보지 말고, 한번 해보시길 추천 드립니다. 감사합니다.
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁 드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치 하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]
'파이썬 (Python) > 크롤링 (Crawling)' 카테고리의 다른 글
| Python 파이썬 인스타그램 사진 크롤링 구현하기 (0) | 2021.02.28 |
|---|---|
| 머신 러닝(Machine Learning) - 챗봇(Chatbot) 만드는 방법 + chatterbot 라이브러리 설치하는 방법 (0) | 2021.02.28 |
| Python 파이썬 HTTP Error 406 : Not Acceptable 솔루션 User Agent 선언 + 멜론 차트 크롤링 하기 (0) | 2021.02.27 |
| 파이썬 Python 웹사이트 이미지 파일을 가져 오는 크롤링하기 (2) | 2021.02.27 |
| 파이썬 Python 웹사이트 컨텐츠 크롤링하기 (0) | 2021.01.30 |




댓글