안녕하세요, 오늘 포스팅 할 내용은, 크롤링 시, 저희가 원하는 HTML 내용이 잘 안가져 와지는 현상 및 멜론 차트 100곡을 크롤링하는것에 대해서 포스팅 하려고 합니다. 멜론 차트 100곡을 크롤링이라는 실습을 통해서 설명을 더 쉽게 하기 위한 것입니다.

그럼 라이브러리부터 선언하는 것 부터 시작해서 크롤링 시, 저희가 원하는 HTML 내용이 잘 안가져 와지는 현상 및 멜론 차트 100곡을 크롤링하는것에 대해서 포스팅을 시작하도록 하겠습니다.
1. 크롤링을 위한 기본 Python Library
1) import urllib.request
: 크롤링을 하는 Site에 접속하기 위한 Library
2) from bs4 import BeautifulSoup
: 정의한 URL을 이용하여, HTML을 읽어 오는 Code
2. 멜론차트 크롤링 하기
: 일단 아래와 같이 멜론에 접속하여, 멜론차트를 클릭을 합니다. 그러면, 현재 멜론에서 정리해놓은 멜론 차트 목록이 보이게 되실 겁니다. 일단 이 멜론차트의 URL를 복사하셔서 아래와 같이 Code를 작성을 합니다.
- 멜론 사이트 : https://www.melon.com/
==================================================================================
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
urladdress1 = 'https://www.melon.com/chart/index.htm'
# 검색어를 입력하고 나서 나오는 결과 창의 URL을 받는 변수
modi01 = urllib.request.Request(urladdress1)
htmlcontent1 = urllib.request.urlopen(modi01).read()
verification1 = BeautifulSoup(htmlcontent1, 'html.parser')
# 정의한 URL을 이용하여, HTML을 읽어 오는 Code
print(verification1)
==================================================================================
- 위 코드를 실행을 시켜 보면 아래와 같이 Error 메시지를 보실 수 있습니다. 잘 살펴 보면, “HTTP Error 406 : Not Acceptable” 이라고 되어 있죠. 이 부분은, 해당 사이트에서, 사람이 아닌 로봇을 인식해서, 크롤링을 하는 것을 막아서 이런 Error가 뜹니다. “그럼 내가 사람이다, 멜론아 내가 사람이야” 라고 이렇게 애기를 해줘야겠죠.

- 위의 Error 사항을 제거 하기 위해서는, 아래 항목을 첨부 해주시면 됩니다.
“header01 = { 'User-Agent' : 'Mozilla/5.0' }"
- 해당 User Agent Information은 아래 Site에서, 현재 사용하는 환경에 맞게, 선언을 받을 수 있습니다. 참조 부탁 드립니다.간단하게 접속 후 보이는 화면에 대해서 설명해 드리면, 현재 접속한 Browser에 맞게, 자동으로 인식해서, User Agent String 을 뿌려 줍니다. 이걸 그대로 복사해서 해당 변수에 Assign 해주시면 됩니다.
- User Agent Code Assign Site : http://www.useragentstring.com/
- 이제 그럼 위에 User Agent String까지 입힌 Code를 넣어서 실행 시켜 보겠습니다. 주의해야 할 사항은, “modi01” 변수에, 위에 “User Agent String” 이 있는 “header01” 를 Header로 적용을 시켜줘야 합니다. 자세한 사항은, 아래 Code 참조 하시면 됩니다.
==================================================================================
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
# 검색어를 입력하고 나서 나오는 결과 창의 URL을 받는 변수
urladdress1 = 'https://www.melon.com/chart/index.htm'
# header01 에 Header의 Information을 넣어줌.
header01 = { 'User-Agent' : 'Mozilla/5.0'}
# Header의 속성에 "header01" 변수를 선언해 줌.
modi01 = urllib.request.Request(urladdress1, headers =header01)
htmlcontent1 = urllib.request.urlopen(modi01).read()
verification1 = BeautifulSoup(htmlcontent1, 'html.parser')
print(verification1)
==================================================================================
- 위 코드를 실행 시켜보면, 엄청난 HTML의 내용이 출력이 되는 걸 보실 수 있습니다. 이때, 저희는 이 많은 내용을 보고 싶은 게 아니고, 특정 내용만 보고 싶기 때문에 이 부분에 대한, 항목을 검사하기 위해서, 개발자 도구를 사용할 예정입니다. Chrome을 실행 시켜 해당 사이트의 개발자 도구를 실행합니다. 그러면 오른쪽에 개발자 도구 창이 뜨면서 현재 보이는 사이트에 해당하는 구조 Code가 보이기 됩니다.
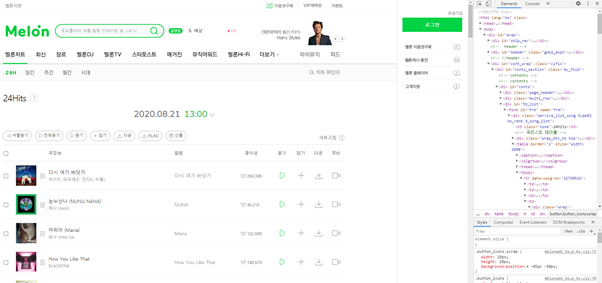
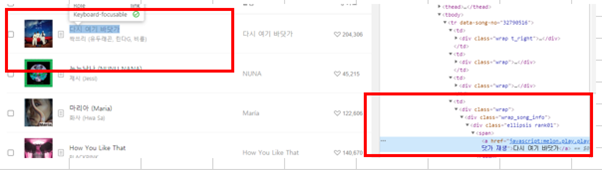
- 여기에서 저희는 노래의 제목과 가수의 내용만 크롤링 하도록 하겠습니다. 검색 도구를 이용하여, 해당 항목을 검색을 해보면, 해당 Class를 찾을 수 있으며, 그 Class 항목을 이용하여, 아래와 같이 Code를 작성 할 수 있습니다.
============================================================
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
# 검색어를 입력하고 나서 나오는 결과 창의 URL을 받는 변수
urladdress1 = 'https://www.melon.com/chart/index.htm'
# header01 에 Header의 Information을 넣어줌.
header01 = { 'User-Agent' : 'Mozilla/5.0'}
# Header의 속성에 "header01" 변수를 선언해 줌.
modi01 = urllib.request.Request(urladdress1, headers =header01)
htmlcontent1 = urllib.request.urlopen(modi01).read()
verification1 = BeautifulSoup(htmlcontent1, 'html.parser')
# 노래 제목을 불러오기 위한 Class Assign
Sorted_Data1 = verification1.select('.ellipsis.rank01')
# 제목에 맞게 가수 이름을 불러오기 위한 Class Assign
Sorted_Data2 = verification1.select('.ellipsis.rank02')
int01 = 0
# 전체 항목 개수를 Count 하기 위해서 변수 int01에 개수 값 Assign
for j in Sorted_Data1:
int01 = int01 + 1
print('===================크롤링 할 총 개수는====================')
print('크롤링 할 총 개수는 :', int01)
print('==============노래와 가수 항목 출력=======================')
# 노래와 가수 모두 크롤링 해서 뿌려주기
for i in range(int01):
print(str(i+1)+'번째', Sorted_Data1[i].a.text, end= " ")
print(Sorted_Data2[i].a.text)
print('=======================================================')
==============================================================
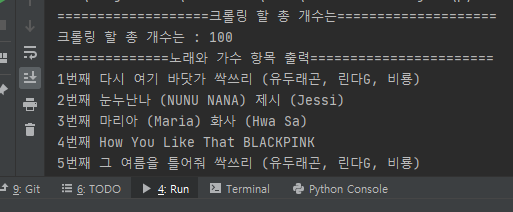
- 위 코드를 실행 시켜 보면 아래와 같이 출력 되는 걸 확인 하실 수 있습니다. 너무 길어서, 첫번 째 항목들과 마지막 항목들만 snap shot으로 붙여 넣게 하였습니다.
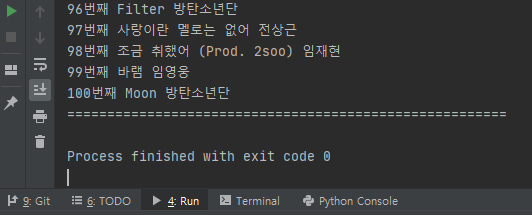
이상입니다. 지금까지 크롤링 시, 저희가 원하는 HTML 내용이 잘 안가져와지는 현상을 멜론 차트 100곡을 크롤링이라는 실습을 통해서 설명을 드렸습니다.
위에서 설명 드린 것 처럼, 크롤링으로 인해, 사이트의 과부하가 걸릴 수 있어서 그런지, 크롤링을 막아 놓은 케이스도 종종 발견을 하였습니다. 이 부분에 대해서는, 위에서 “나 사람이다” 라고 지정을 해놓으셔야 크롤링 수행이 가능합니다. 알면 10분만에 끝날 일이, 2~3시간 투자해서 그 방법을 알아내는 게, 프로그래밍을 하는 사람들이 겪는 가장 큰 고통인 거 같습니다. 하지만 한 번 그렇게 하면, 쉽게 잊어 먹지 않는 장점도 있고, 이게 습관이 되야, 다른 상황에서도, 열심히 찾으려는 끈기를 기르지 않을까 합니다. 그럼 여기에서 마무리 하도록 하겠습니다. 오늘도 프로그래밍 공부하시느라고 수고 하셨습니다. 항상 애기하지만 같이 고민 하고 같이 공부해서 같이 성장하시죠! 감사합니다.
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁 드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치 하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]
'파이썬 (Python) > 크롤링 (Crawling)' 카테고리의 다른 글
| Python 파이썬 인스타그램 사진 크롤링 구현하기 (0) | 2021.02.28 |
|---|---|
| 머신 러닝(Machine Learning) - 챗봇(Chatbot) 만드는 방법 + chatterbot 라이브러리 설치하는 방법 (0) | 2021.02.28 |
| 파이썬 Python 웹사이트 이미지 파일을 가져 오는 크롤링하기 (2) | 2021.02.27 |
| 파이썬 Python 별도의 URL 없이 검색어로 크롤링 하는 방법 (0) | 2021.02.27 |
| 파이썬 Python 웹사이트 컨텐츠 크롤링하기 (0) | 2021.01.30 |




댓글