안녕하세요, 이번 포스팅은 인스타그램 사진을 크롤링 하는 방법에 대해서 기재해보도록 하겠습니다. 이전에 포스팅한 이미지 크롤링하는 방법을 이용하여 구현해보도록 하겠습니다.

요즘 크롤링에 대해서, 관심이 증대되고 있는 상황에서, 이미지나 컨텐츠 크롤링을 시도해보시고 자신이 원하는 사항을 구현하는데 사용하시면 될 거 같습니다.
인스타그램 이미지 크롤링 하기
: 그럼, 일단 코딩을 하기 위해서, 파이참을 실행을 합니다. 그리고, 파이참 실행과 동시에, 기존에 자신이 작업하고 있는 코딩 프로그램 폴더에 새로운 파이썬 파일을 하나 만듭니다. 아래 Snap Shot을 보시면, "Demostration_Crawling_Insta.py" 파일을 보실 수 있습니다.
그럼 슬슬 코딩을 짜볼까요. 일단 이번 작업을 위해서 활용할 함수 및 Function은 크게 아래와 같습니다.
1. selenium
- Terminal 창에서 설치를 해주셔야 합니다. 설치 구문은 아래와 같습니다.
: pip install selenium
2. BeautifulSoup(4)
- Terminal 창에서 설치를 해주셔야 합니다. 설치 구문은 아래와 같습니다.
: pip install BeautifulSoup4 (꼭, "4"를 붙여주셔야 합니다.)
3. Chromedriver
3번 항목인, Chromedriver 에 대해서는 아래 Link를 참조하시어, 미리 다운을 받아 놓으셔야 합니다.
그럼 Chromedriver 까지, 현재 User가 사용하고 있는 Chrome Version에 맞게 다운 받아 놓으시면, 코딩 짜기 전 준비는 거의다 끝난 셈입니다.
첫번 째로, 필요한 함수 및 관련 Package 선언을 먼저 해주셔야 합니다.
====================================================================
import time # 인터넷 속도가 느릴 경우 렉이 걸리고, 컴퓨터가 멈춤 현상이 일어난다. 이를 방지하기 위해서, 중간에 쉬는 시간을 주어, 컴퓨터 멈춤 현상을 방지하는 역할을 하기 위해서 선언.
from bs4 import BeautifulSoup # 불러온 데이터를 구분지어, 원하는 데이터를 출력 할 수 있게 하는 함수.
from selenium import webdriver # Chromedriver 를 사용하여, 자동화 시스템 구동.
from urllib.request import urlopen # URL를 인식 후, 열어 주는 역할
from urllib.parse import quote_plus # 우리가 사용하는 언어 방식을 컴퓨터가 인식할 수 있는 ASIIC 형태로 자동 변형해 줌====================================================================
- 그리고 아래와 같이 Main Code 작성을 하셔야 합니다.
====================================================================
testurl_1 = "https://www.instagram.com/explore/tags/" # 일단 인스타그램의 기본 URL를 testurl_1 로 받습니다.
testurl_2 = input("Please input the word to search for") # 검색하고 싶은 단어를 입력 할 수있는 변수 선언
testurl_3 = testurl_1 + quote_plus(testurl_2) # 우리가 사용하는 언어 방식을 컴퓨터가 인식할 수 있는 ASIIC 형태로 자동 변형해
driver01 = webdriver.Chrome() # Chromedriver 를 사용한다는 선언.
driver01.get(testurl_3) # 어느 URL에서 사용하는지에 대해서 입력.
himl01 = driver01.page_source
Source01 = BeautifulSoup(himl01)
time.sleep(3)
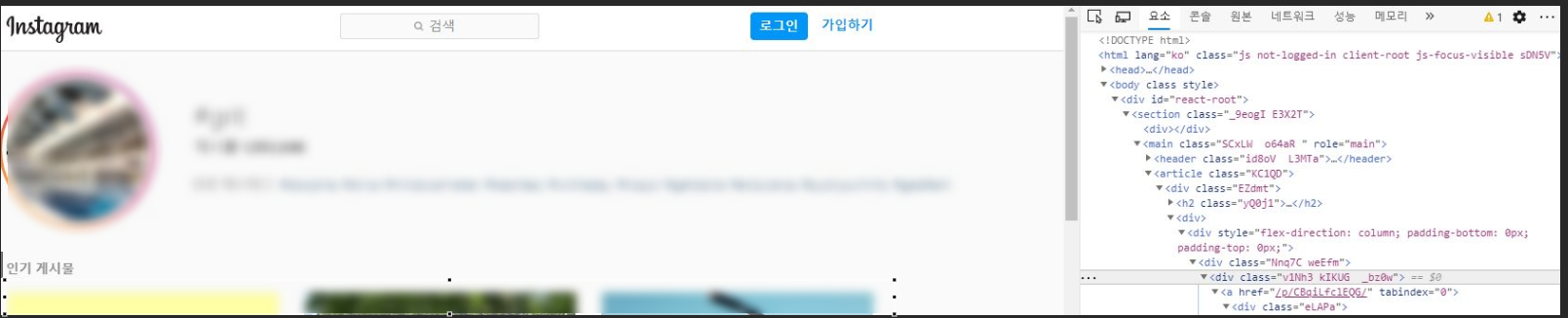
Dem_insta = Source01.select('.v1Nh3.kIKUG._bz0w') # 페이지 검사를 통해서 검토한 class 이름을 입력 및 선택함. 아래 Snap Shot 참조
x = 1
for i in insta:
print("https://www.instagram.com/" + i.a['href'])
img01 = i.select_one('.KL4Bh').img['src'] # 사진 Source를 불러 올 수 있는 class 정보를 입력.
with urlopen(img01) as q:
with open('./' + testurl_2 + str(x) + 'jpg', 'wb') as p:
img = q.read() # 해당 주소 Source를 읽는다.
p.write(img) # 입력한 이름으로 사진을 저장한다.
x += 1 # 숫자 1씩 증가
print(img01)
print()
driver01.close()
====================================================================
위의 Code를 통해서, 구현하게 되면, 아래와 같이 구현 결과를 얻을 수 있습니다.
- 검색 키워드를 입력하는 창이 뜨고, 검색 키워드를 입력 합니다.
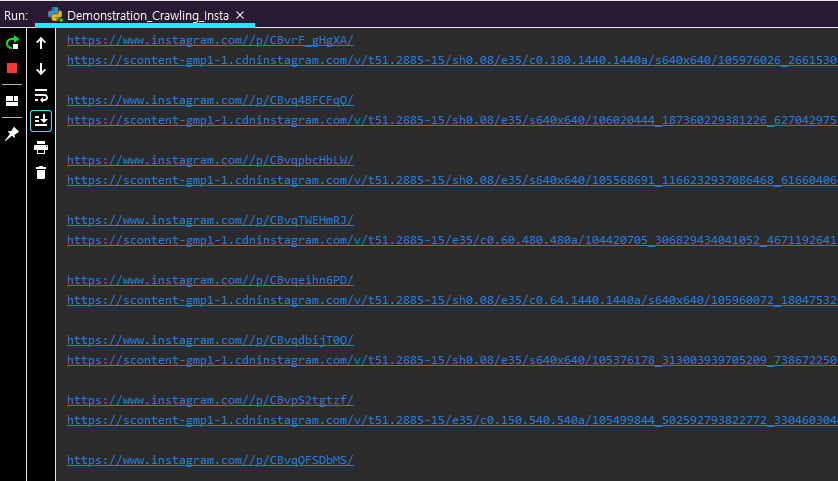
- 사진 Source 주소가 차례 차례 출력이 되는 걸 확인 하실 수 있습니다. 관련 키워드에 맞게 인스타그램 홈페이지도 열립니다. (해시태그 검색 위주 홈페이지 입니다. 참조 하세요. 왜냐하면, 메일 홈페이지는 아이디 입력창이 먼저 뜨니까, 좀 복잡하게 꾸려야 합니다.)
- 이렇게 출력되는 것과 동시에, 지정된 폴더창에 사진이 자동으로 저장이 됩니다.
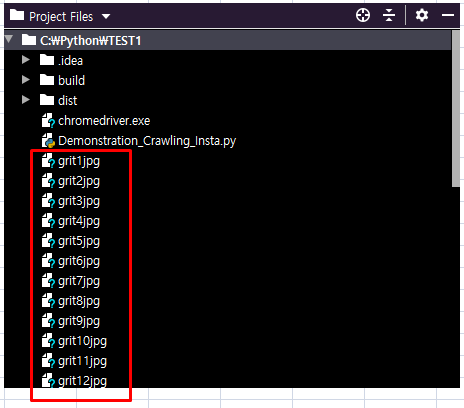
지금까까지 파이썬을 이용하여 인스타그램의 이미지를 크롤링하는 방법에 대해서 포스팅을 작성하였습니다. 이렇게 사진 파일까지 저장된 걸 확인 해보시면, 작업은 끝난 것입니다. 정말 수고 하셨습니다. 저도 처음에, 했을 때, 홈페이지에 HTML 검토하는 데도, 시간이 너무나도 많이 걸렸습니다. 이것 저것 다 해보고, 결국 찾은 Source Class 를 통해서 구현이 가능했습니다. 여러분에게도 많은 도움이 되었으면 하네요. 직접 실습해보시면 더 이해가 빠르실 겁니다. 같이 성장하시죠. 감사합니다.
제 Posting이 조금이나마 정보 전달에 도움이 되셨길 빌며, 되셨다면, 구독, 댓글, 공감 3종 세트 부탁 드립니다. 감사합니다.
[저작권이나, 권리를 침해한 사항이 있으면 언제든지 Comment 부탁 드립니다. 검토 후 수정 및 삭제 조치 하도록 하겠습니다. 그리고, 기재되는 내용은 개인적으로 습득한 내용이므로, 혹 오류가 발생할 수 있을 가능성이 있으므로, 기재된 내용은 참조용으로만 봐주시길 바랍니다. 게시물에, 오류가 있을때도, Comment 달아 주시면, 검증 결과를 통해, 수정하도록 하겠습니다.]
'파이썬 (Python) > 크롤링 (Crawling)' 카테고리의 다른 글
| 웹페이지 크롤링 + Link로 연결되어 보여주거나 호출로 보여지는 Data를 크롤링 하는 방법 (1) | 2021.03.04 |
|---|---|
| 머신 러닝(Machine Learning) - 챗봇(Chatbot) 만드는 방법 + chatterbot 라이브러리 설치하는 방법 (0) | 2021.02.28 |
| Python 파이썬 HTTP Error 406 : Not Acceptable 솔루션 User Agent 선언 + 멜론 차트 크롤링 하기 (0) | 2021.02.27 |
| 파이썬 Python 웹사이트 이미지 파일을 가져 오는 크롤링하기 (2) | 2021.02.27 |
| 파이썬 Python 별도의 URL 없이 검색어로 크롤링 하는 방법 (0) | 2021.02.27 |




댓글